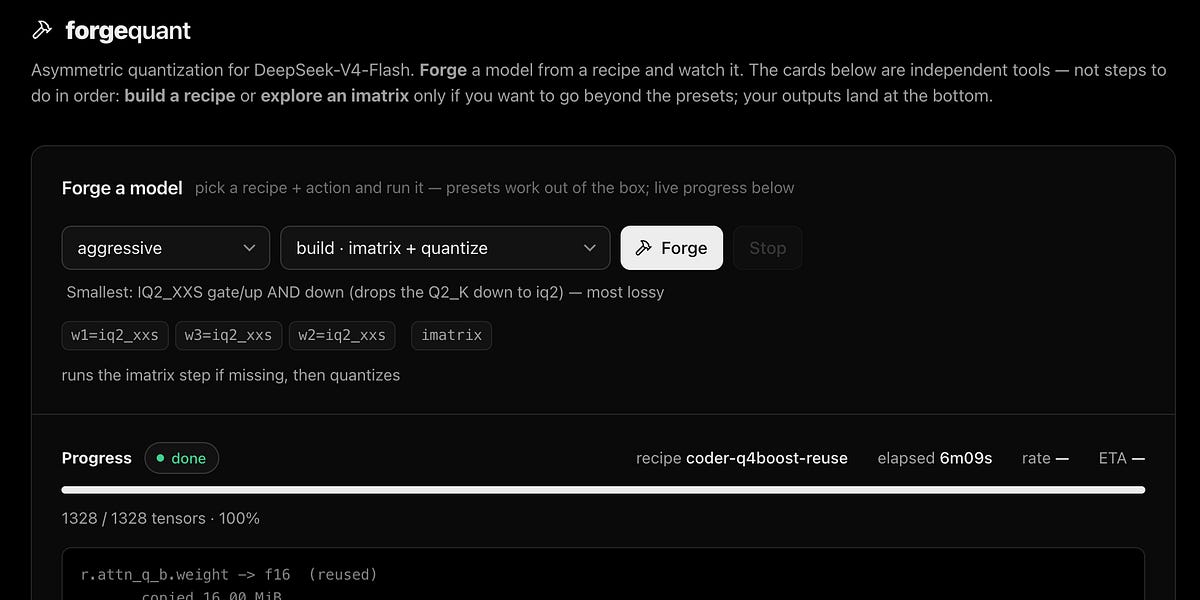
Разработан метод инкрементального квантования локальных LLM, позволяющий сократить время пересборки вариантов моделей с 80 до ~5 минут. Технология использует сравнение хэшей (fingerprints) для пропуска неизменных тензоров, что радикально ускоряет процесс подбора оптимальных параметров.
Что произошло
Разработчики представили технологию инкрементального квантования, которая ускоряет процесс оптимизации локальных языковых моделей в 14 раз. Вместо полной пересборки весов система идентифицирует неизменные части модели через хэширование и работает только с изменившимися тензорами. Это позволяет сократить цикл итераций с 80 минут до примерно 5 минут.
Контекст
При квантовании моделей для работы на локальном оборудовании часто требуется подбирать баланс между размером модели и ее качеством (bit-width). Традиционный подход требует полного цикла обработки при каждом изменении параметров, что занимает значительное время. Новый метод позволяет использовать гранулярное квантование (mixed-precision), например, сохраняя высокую точность (8 бит) для критически важных слоев-маршрутизаторов и применяя агрессивное сжатие (2 бита) для экспертов в архитектурах MoE.
Почему это важно для индустрии
Метод значительно ускоряет цикл разработки и прототипирования оптимизированных моделей, делая создание кастомизированных Edge AI решений более доступным. В долгосрочной перспективе это может привести к интеграции инкрементального квантования в такие инструменты, как llama.cpp или AutoGPTQ, и развитию концепции самоадаптирующегося квантования, где модель динамически меняет точность в зависимости от доступных вычислительных ресурсов.
Почему это важно для пользователей
Процесс подбора оптимальной версии модели, которая бы помещалась в объем видеопамяти (VRAM) без существенной потери качества, станет на порядок быстрее. Это делает глубокую настройку нейросетей под конкретное домашнее железо доступной даже для пользователей без профессиональных вычислительных мощностей, превращая многочасовую задачу в минутную.
Что пока неизвестно / ограничения
Текущие обсуждения фокусируются на скорости разработки и оптимизации, не уделяя достаточного внимания возможным эксплуатационным рискам при использовании новых методов сжатия.
Источники
Автор
Look at AI, редакция