
Команда инфраструктуры ML в Яндексе разработала Dev Cluster — сервис для динамического управления GPU-ресурсами, который позволяет инженерам мгновенно переключаться между различными конфигурациями вычислительных мощностей без потери прогресса.


Что произошло
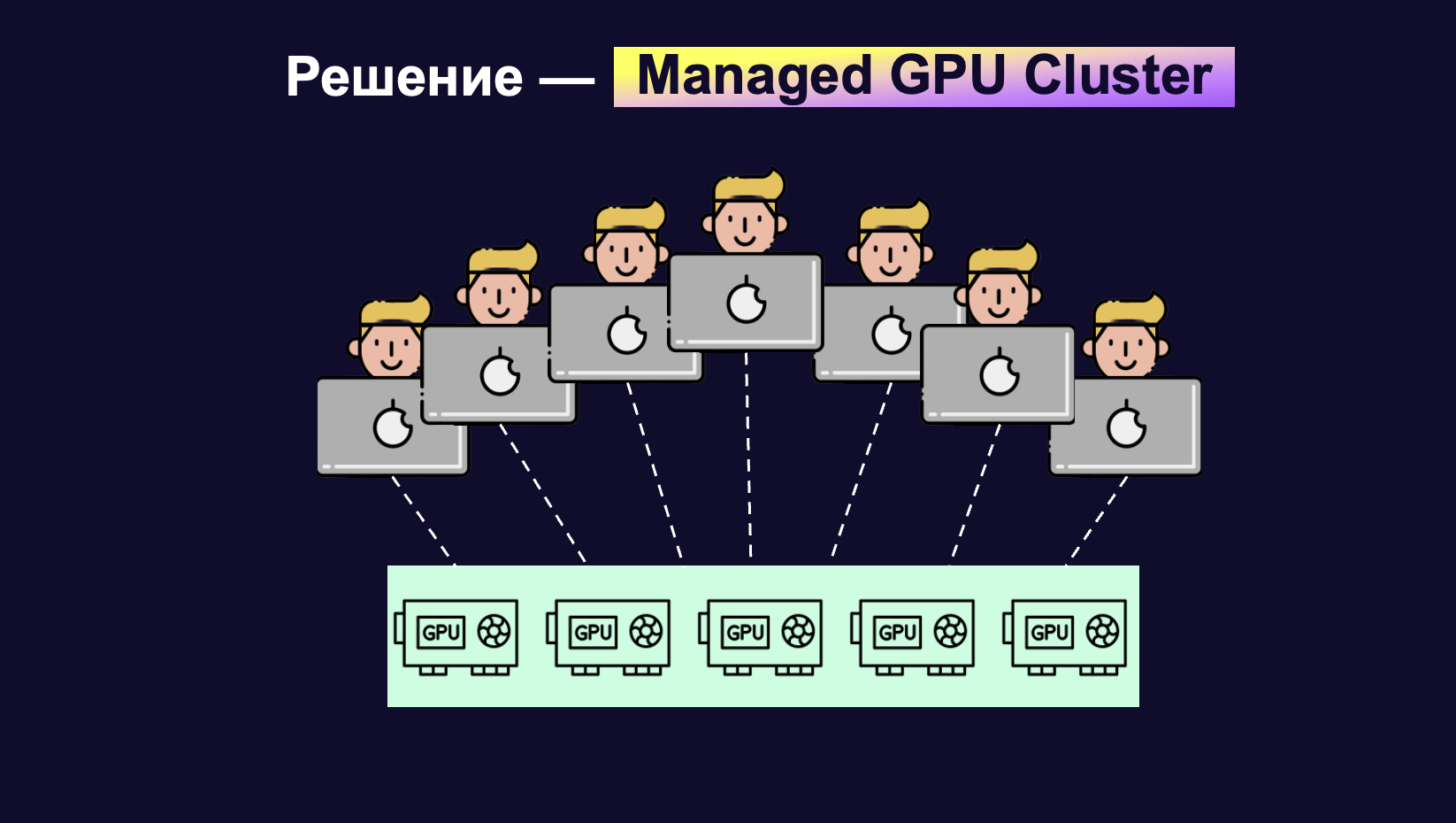
Яндекс запустил Dev Cluster, сервис, построенный на стеке Go, gRPC и PostgreSQL, который автоматизирует распределение квот и управление GPU-ресурсами. Система внедряет механизм Suspend, позволяющий сохранять состояние рабочего окружения при переключении между CPU-разработкой и различными GPU-конфигурациями (от одной карты до целого кластера) в несколько кликов.
Контекст
Традиционно управление ресурсами в ML-командах часто сводится к ручному распределению общих виртуальных машин (модель «совместного проживания»), что приводит к простоям оборудования и сложностям при масштабировании. Dev Cluster переводит этот процесс в плоскость автоматизированного контейнеризированного управления ресурсами по запросу.
Почему это важно для индустрии
Для индустрии это означает оптимизацию использования дорогостоящего оборудования и снижение стоимости разработки ИИ-продуктов. Переход к модели «on-demand resources» и абстракция инфраструктуры позволяют эффективно масштабировать LLM-эксперименты и снижать операционные издержки на содержание GPU-парков.
Почему это важно для пользователей
ML-инженеры получают возможность быстро тестировать гипотезы на малом количестве GPU и мгновенно масштабироваться на кластер, не тратя время на сложную настройку окружения или согласование ресурсов с коллегами. Механизм Suspend обеспечивает непрерывность экспериментов, сохраняя весь прогресс в коде при смене железа.
Что пока неизвестно / ограничения
Существуют вопросы относительно обеспечения полной безопасности и изоляции данных при таком динамическом распределении ресурсов, что является критическим аспектом для корпоративной среды.
Источники
Автор
Look at AI, редакция