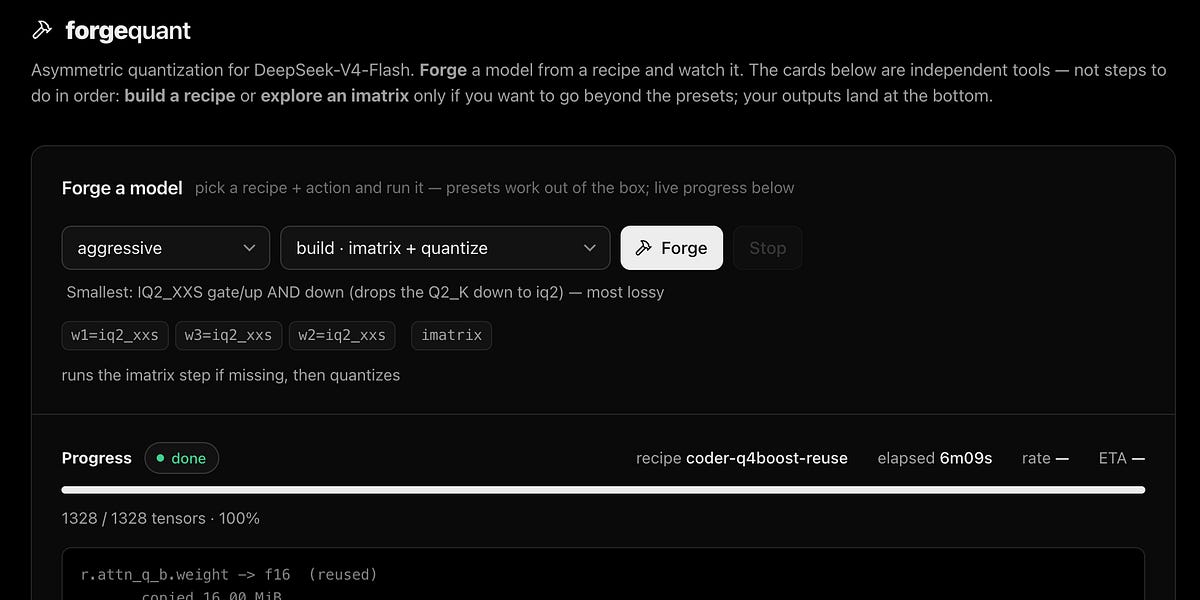
🚀 Квантование LLM ускорилось в 14 раз
Разработан метод инкрементального квантования локальных LLM, сокращающий время пересборки моделей с 80 до 5 минут. Технология использует сравнение хэшей (fingerprints) тензоров, позволяя пропускать неизменные части при пересборке.
🌍 Метод ускоряет цикл оптимизации локальных моделей, позволяя разработчикам быстро находить баланс между качеством и размером под конкретные задачи.
👤 Процесс подбора параметров модели для домашнего железа станет намного быстрее, исключая многочасовое ожидание после каждой правки.
Источник 1: https://andreaborio.substack.com/p/re-quantizing-a-local-model-14-faster