An investigation into ChatGPT's search mechanisms has identified four primary data retrieval pipelines that determine which resources the neural network relies on when generating responses.
What Happened
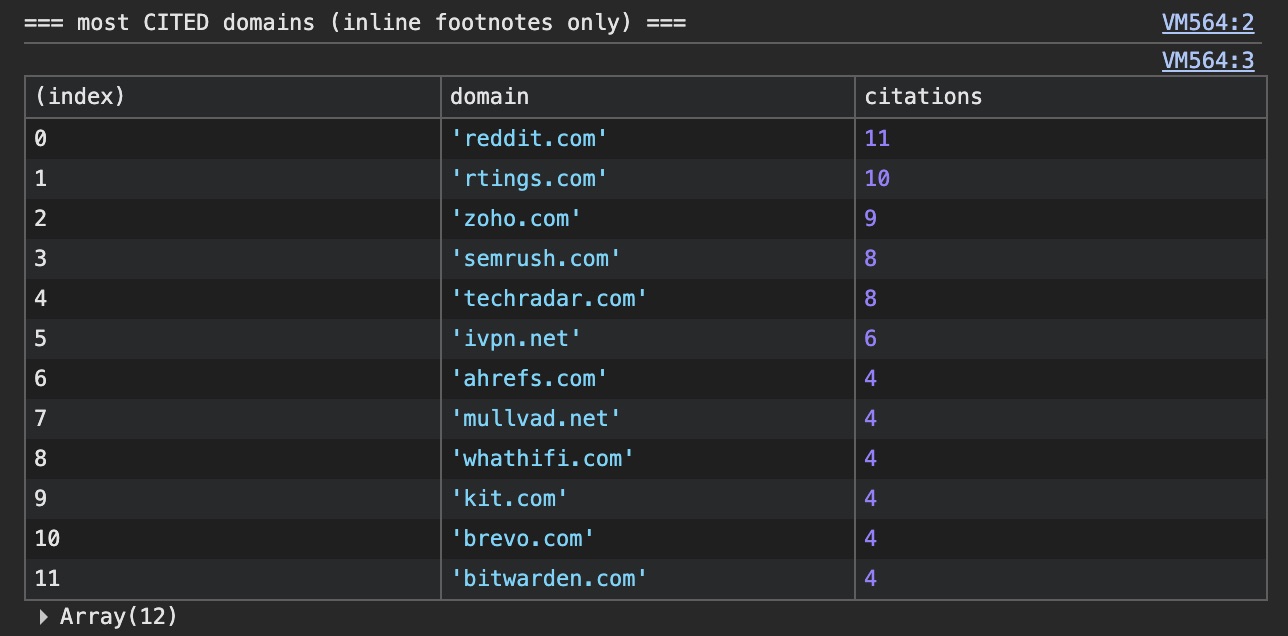
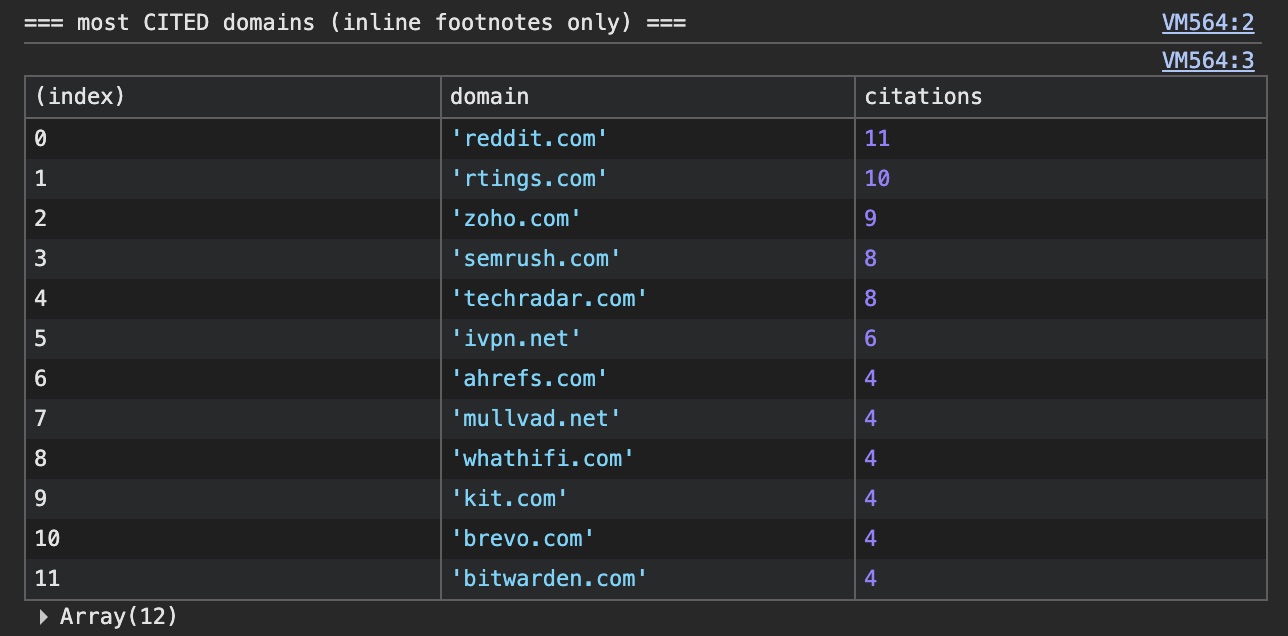
Analysis of ChatGPT's network traffic revealed the use of four types of pipelines via the result_source field: labrador (licensed content, such as Wikipedia and Reuters), bright and oxylabs (commercial scrapers for collecting data from Reddit and local resources), and serp (standard search engine results). The process includes classifying query intent (text, shopping, thinking) and subsequently breaking the task down into atomic checks.
Context
A critical factor in source selection is data "readability." If vital information, such as prices or specifications, is hidden behind complex JavaScript execution or requires image rendering, ChatGPT may ignore a company's official website and instead use data from aggregators or forums like Reddit.
Why It Matters for the Industry
For the industry, this marks the beginning of the GEO (Generative Engine Optimization) era. To remain primary sources for AI, brands must ensure their data is accessible in simple HTML text. Complex frontend architectures with heavy JS can lead to a loss of citability, forcing companies to optimize their websites for the parsing capabilities of LLM agents.
Why It Matters for Users
It is beneficial for users to understand why neural network responses are sometimes built on opinions from Reddit, even when an official product website exists. This knowledge helps in better understanding the logic of AI agents and how they "choose" information to provide answers.
Sources
Author
Look at AI, Editorial Team