🔍 How ChatGPT Selects Data Sources
Research into ChatGPT's search mechanisms has revealed four primary data retrieval pipelines via the result_source field: labrador (licensed media such as Reuters and Wikipedia), bright and oxylabs (commercial scrapers for Reddit and local data), and serp (standard search engine results page).
🌍 An understanding of GEO (Generative Engine Optimization) mechanisms is emerging. To ensure brands remain citation sources, their data must be accessible in simple HTML text rather than solely through dynamic JS; otherwise, neural networks will rely on aggregators and forums.
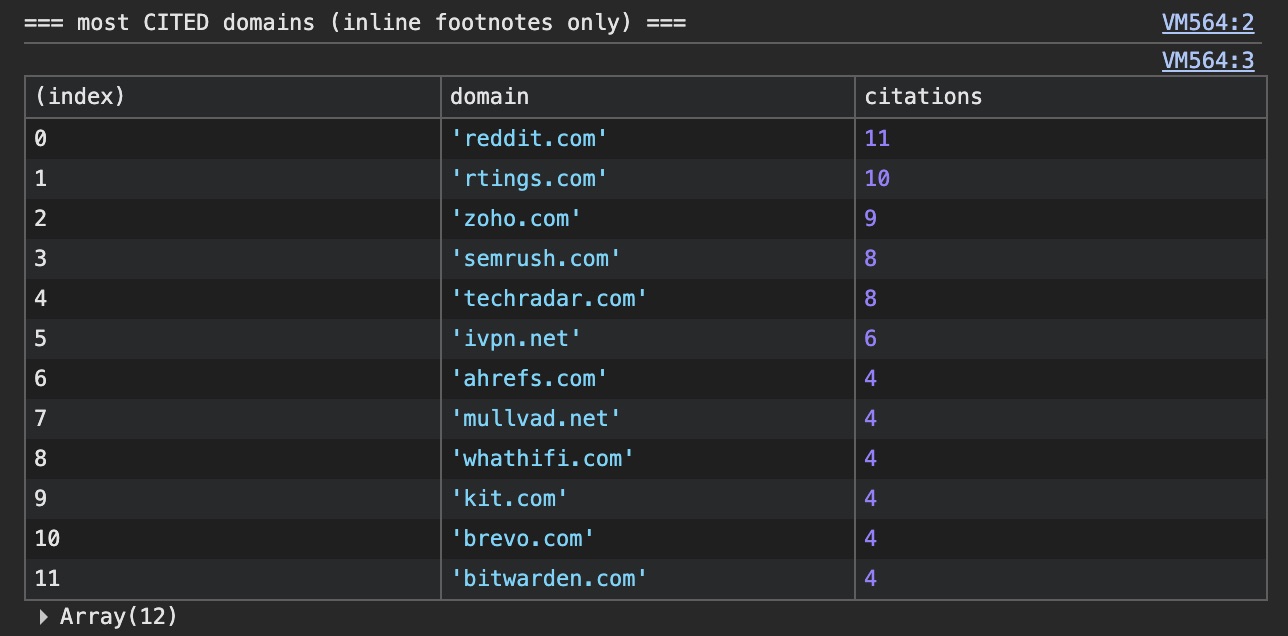
👤 Understanding how ChatGPT "chooses" the truth helps optimize content for AI agents and explains why answers are sometimes built on Reddit, even when a company has an official website.
Source 1: https://suganthan.com/blog/how-chatgpt-picks-sources/