Roboflow has released RF-DETR — a new transformer architecture designed for real-time object detection, segmentation, and keypoint detection (pose estimation). Based on the DINOv2 vision transformer, the model demonstrates outstanding results, combining high accuracy with minimal latency, making it suitable for high-load computer vision systems.
What Happened
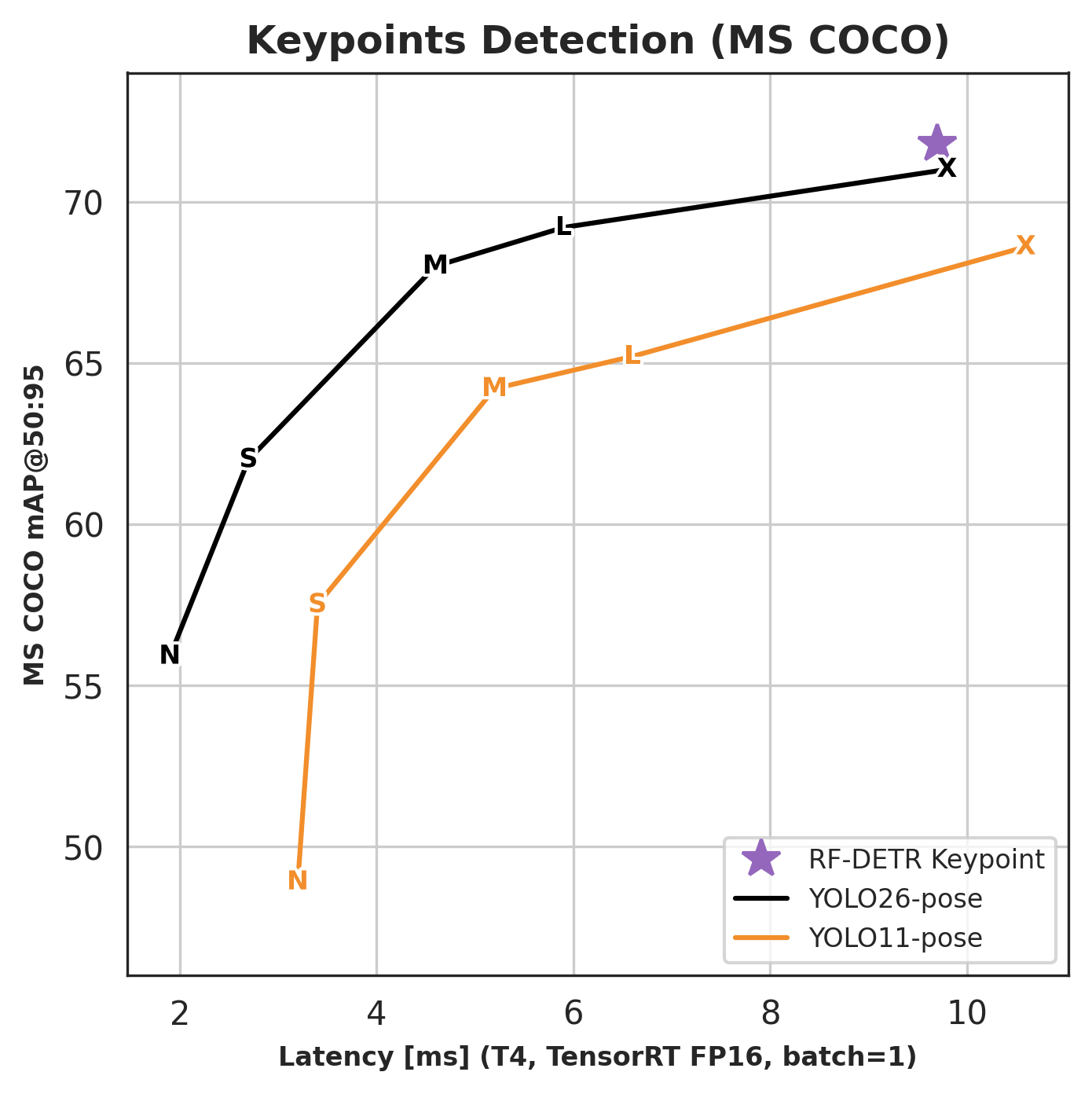
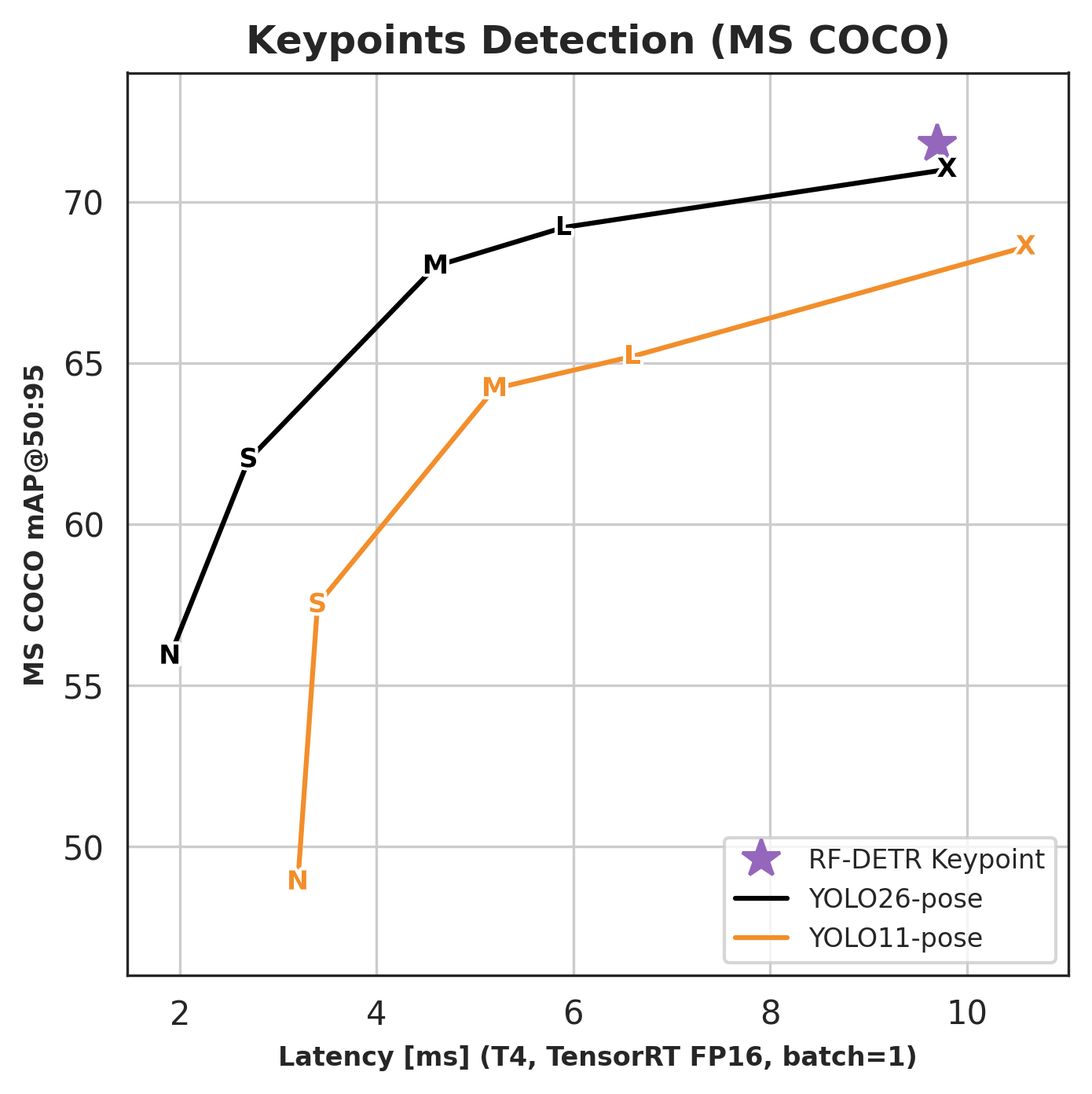
Developers introduced RF-DETR, which achieved a score of 71.8 AP on the COCO dataset with a latency of only 9.7 ms on an NVIDIA T4 GPU. One of the model's key technical features is the generation of a 2D uncertainty ellipse for each detected point, allowing for a visual assessment of the system's confidence in its predictions.
Context
Traditionally, high-accuracy pose estimation tasks required the use of heavy offline models that could not operate in real-time on edge devices. RF-DETR solves this problem by using DINOv2 as a visual backbone to ensure high semantic feature richness, while the transformer architecture proves its effectiveness in scenarios where CNNs previously dominated due to strict latency requirements.
Why It Matters for the Industry
RF-DETR sets a new standard for efficiency in real-time computer vision systems, offering SOTA-level accuracy while maintaining the speed critical for robotics and autonomous systems. The implementation of uncertainty estimation mechanisms moves computer vision from pure recognition into the realm of reliable decision-making systems, which is essential for the commercialization of safe robots and monitoring systems.
Why It Matters for Users
Developers and engineers can use the new rfdetr library to integrate high-precision pose and motion tracking into their pipelines with minimal latency. The solution is available for deployment on consumer or mid-range hardware, such as the NVIDIA T4, significantly reducing the cost of developing high-precision positioning and tracking systems.
Sources
Author
Look at AI, Editorial Team