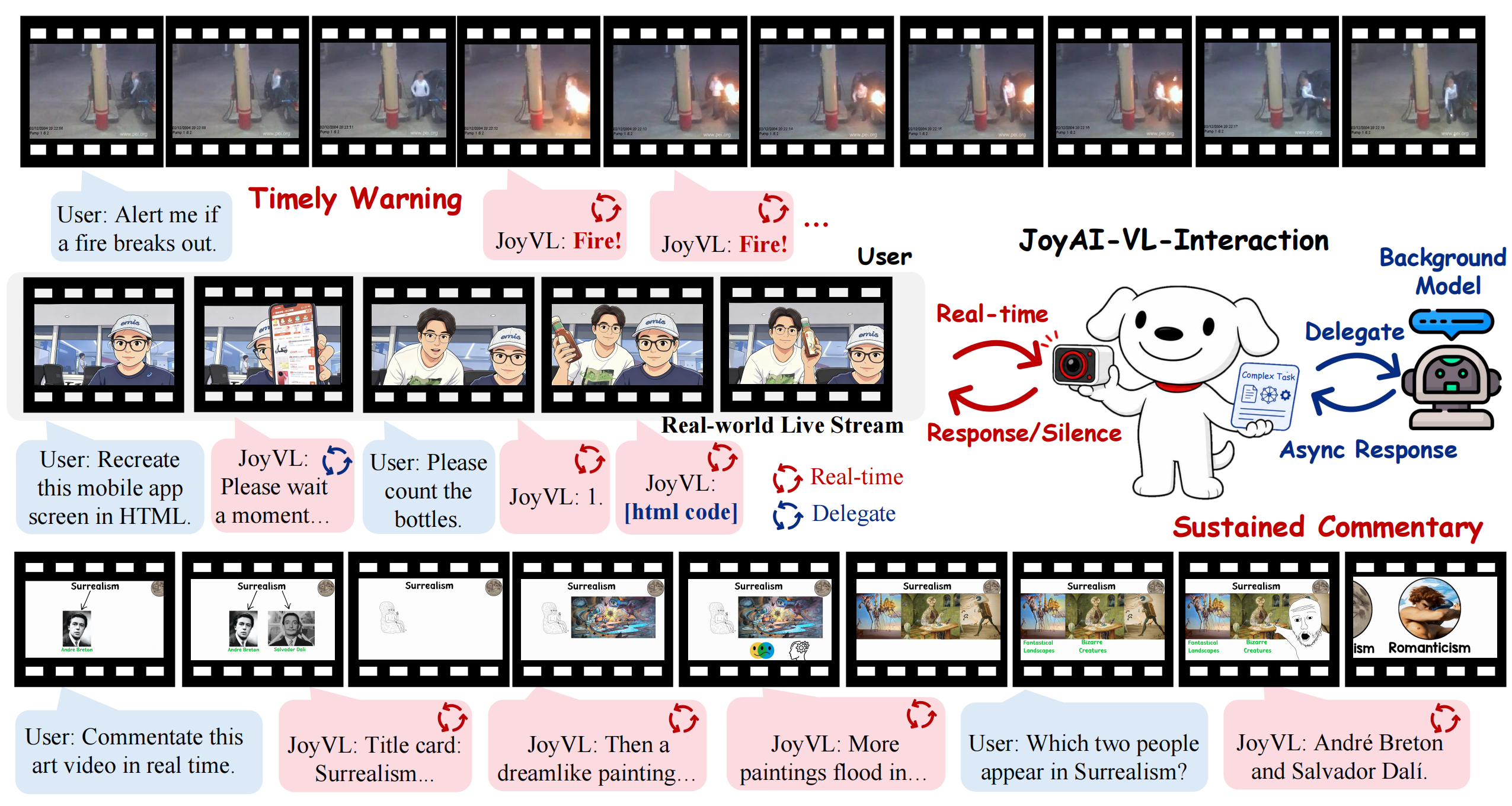
The Joy Future Academy (JD) team has introduced JoyAI-VL-Interaction — the world's first open-source 8B-parameter interactive Vision-Language Model (VLM) capable of operating in real time. Unlike traditional models that only respond to queries, this system makes per-second decisions on how to interact: whether to speak, remain silent, or delegate tasks to background agents.


What Happened
Developers from Joy Future Academy released JoyAI-VL-Interaction, a model trained on more than 4 million temporal clips. The system demonstrates high efficiency in monitoring tasks and rapid response to visual events, showing results comparable to closed proprietary systems such as Gemini and Doubao.
Context
Modern multimodal models typically operate on a "query-response" principle, making them passive tools. JoyAI-VL-Interaction shifts to a "presence agent" architecture, which continuously analyzes the visual data stream, transforming it from a set of individual frames into a coherent context for decision-making.
Why It Matters for the Industry
For the AI industry, this signifies a paradigm shift from reactive chatbots to proactive autonomous agents. The emergence of a high-quality open-source alternative to SOTA solutions in the niche of real-time VLM monitoring creates a foundation for developing intelligent surveillance, navigation, and robotics systems without dependency on closed APIs.
Why It Matters for Users
Users will gain access to a new class of AI assistants capable of independently noticing critical events—such as a person falling or a workflow being completed—and reacting or notifying immediately without waiting for a direct command.
What Is Not Yet Known / Limitations
At this time, uncertainty remains regarding latency, inference costs during continuous data streaming, and security issues related to managing real-time data streams.
Sources
- JoyAI-VL-Interaction: Real-Time Vision-Language Interaction Intelligence
- jd-opensource/JoyAI-VL-Interaction GitHub Repository
Author
Look at AI, Editorial Staff