🎙 WavTTS: прямой синтез аудиоволн
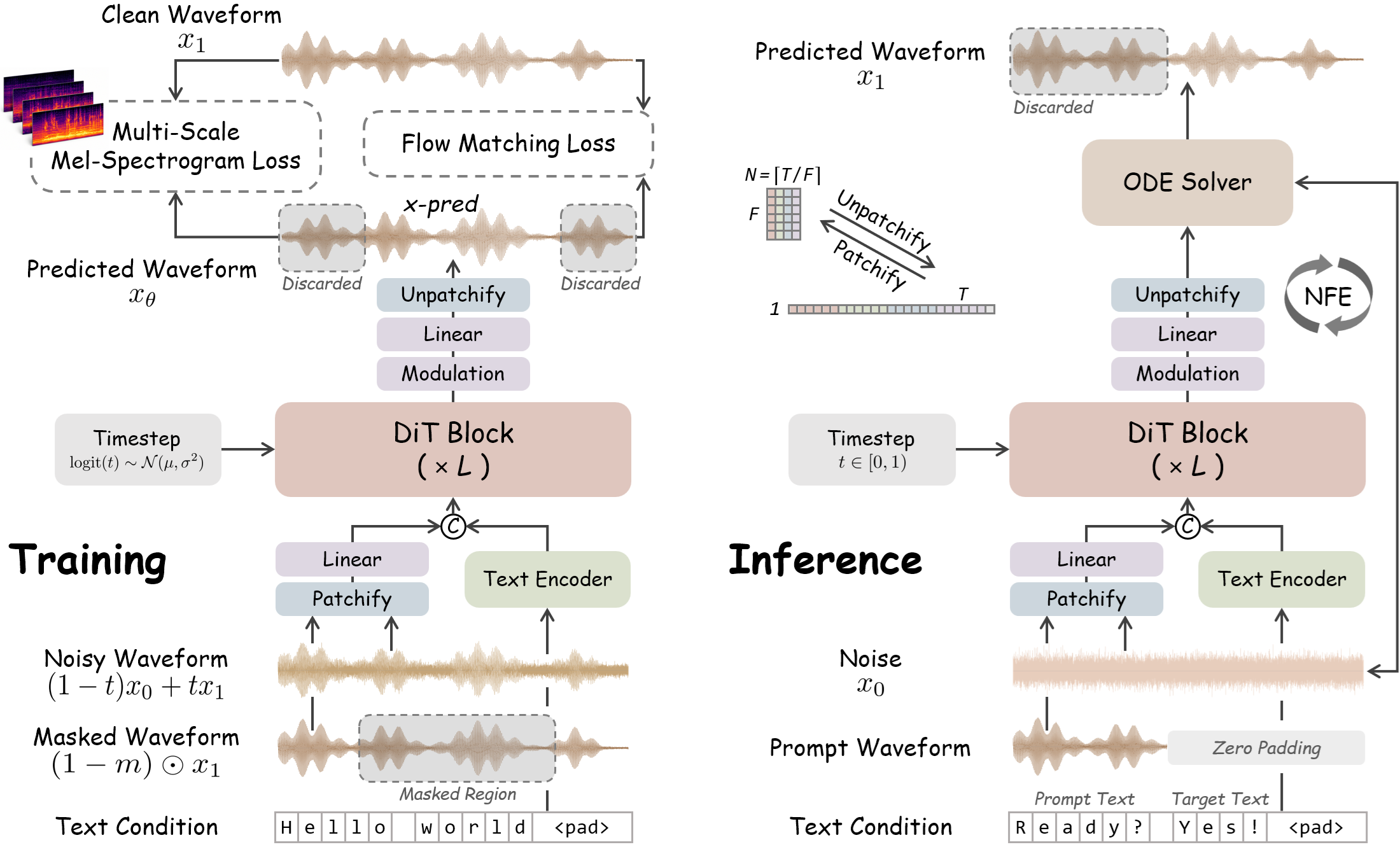
Представлен WavTTS — первый фреймворк для генерации речи (zero-shot TTS), который моделирует сырые аудиоволны напрямую, минуя промежуточные этапы вроде мел-спектрограмм. Модель построена на архитектуре Flow Matching и Diffusion Transformer.
🌍 Переход к прямому моделированию волновой формы устраняет потерю информации и позволяет создавать более точные end-to-end системы синтеза речи.
👤 Это шаг к более естественному клонированию голоса. Проект имеет открытый код (MIT), но веса под CC BY-NC 4.0.
Источник 1: https://wavtts.github.io/ Источник 2: https://github.com/cwx-worst-one/WavTTS