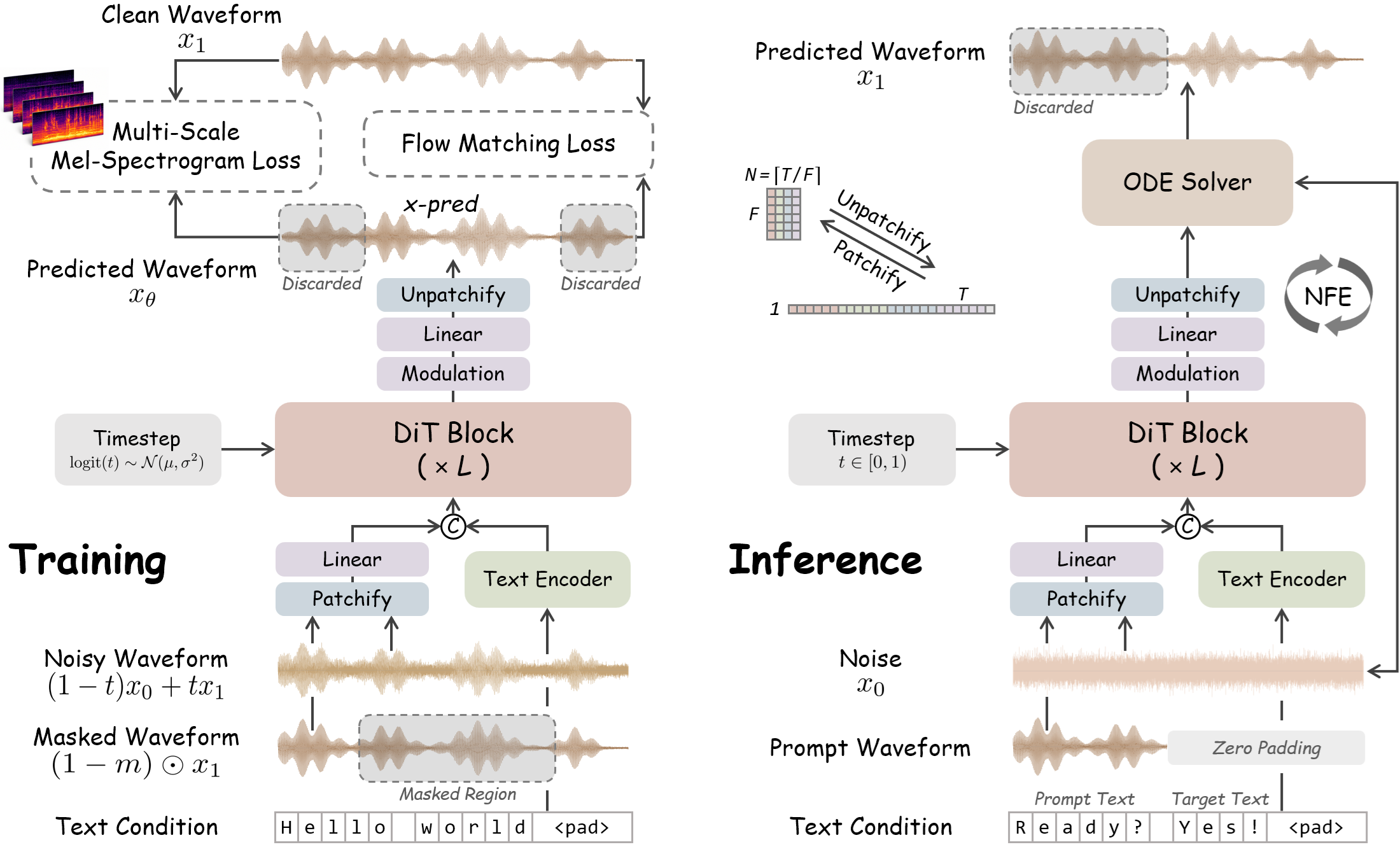
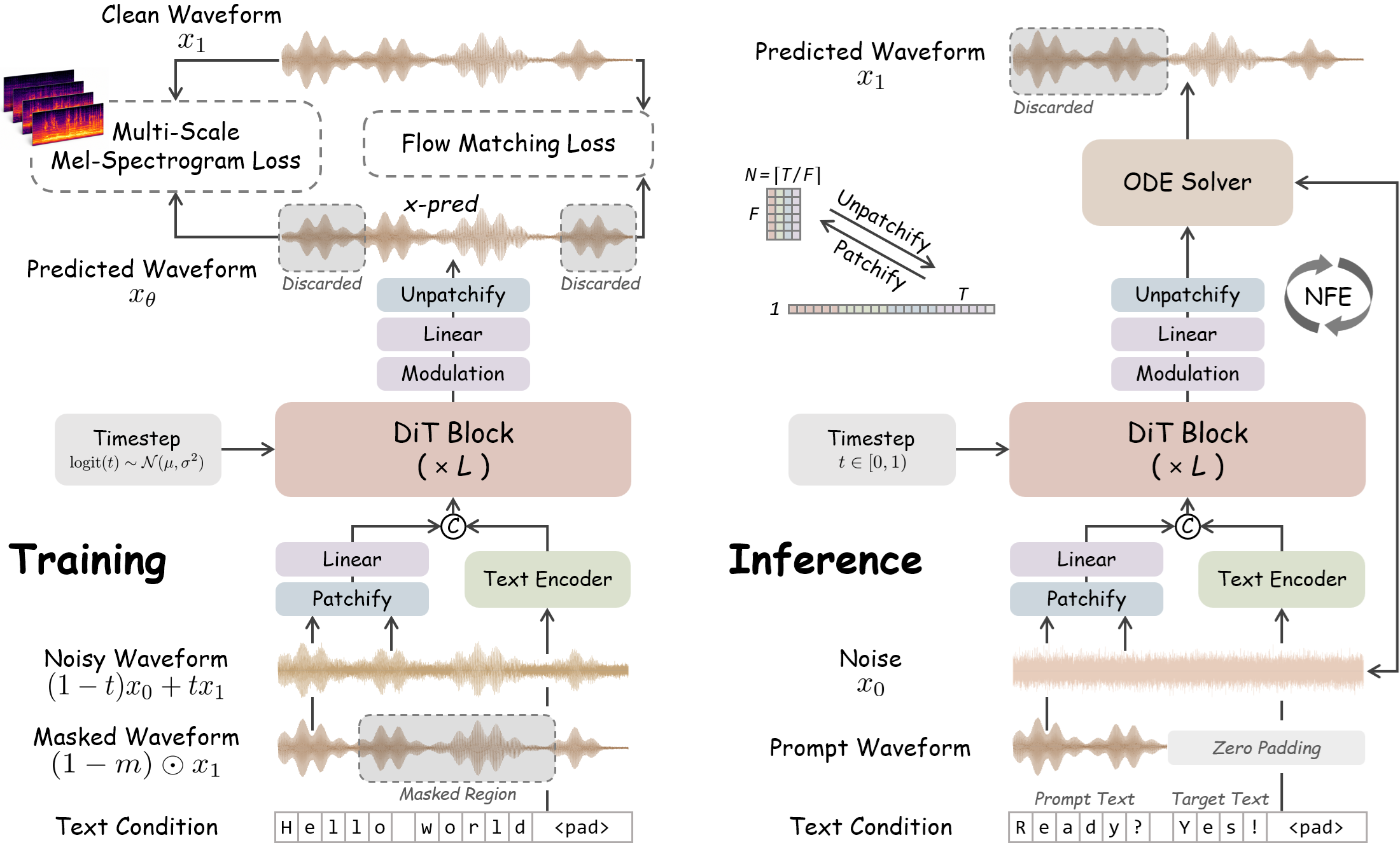
Представлен WavTTS — первый фреймворк для zero-shot генерации речи, который моделирует сырые аудиоволны напрямую, минуя промежуточные этапы вроде мел-спектрограмм. Модель использует архитектуру Flow Matching с Diffusion Transformer (DiT) и стратегию patchification для эффективной работы с длинными последовательностями аудио.

Что произошло
Разработчики представили WavTTS, систему синтеза речи, построенную на базе Flow Matching и Diffusion Transformer. В отличие от традиционных методов, WavTTS обеспечивает высокое качество синтеза при частоте 16 кГц, работая напрямую с raw waveforms. Проект имеет открытый исходный код (лицензия MIT) и доступные веса на Hugging Face.
Контекст
Большинство современных систем синтеза речи используют промежуточные представления, такие как мел-спектрограммы или VAE-латентные пространства. Хотя это упрощает задачу, такой подход неизбежно ведет к потере информации при сжатии сигнала. WavTTS предлагает перейти к end-to-end архитектурам, которые моделируют аудиосигнал целиком.
Почему это важно для индустрии
Переход к прямому моделированию волновой формы позволяет устранить информационные потери, характерные для спектрограммных методов, и создает основу для более точных end-to-end систем. В долгосрочной перспективе это может привести к смене парадигмы в TTS-исследованиях: от гибридных конвейеров к чисто диффузионным моделям прямого моделирования сигнала.
Почему это важно для пользователей
Для пользователей и разработчиков это означает возможность создания более естественного и качественного клонирования голоса в локальных рабочих процессах. Благодаря открытости кода и весов, WavTTS можно интегрировать в такие инструменты, как ComfyUI, для локального запуска высококачественного синтеза без использования облачных API.
Что пока неизвестно / ограничения
Несмотря на открытость кода под лицензией MIT, веса модели распространяются под лицензией CC BY-NC 4.0, что накладывает ограничения на коммерческое использование.
Источники
Автор
Look at AI, редакция