🔍 Как ChatGPT выбирает источники данных
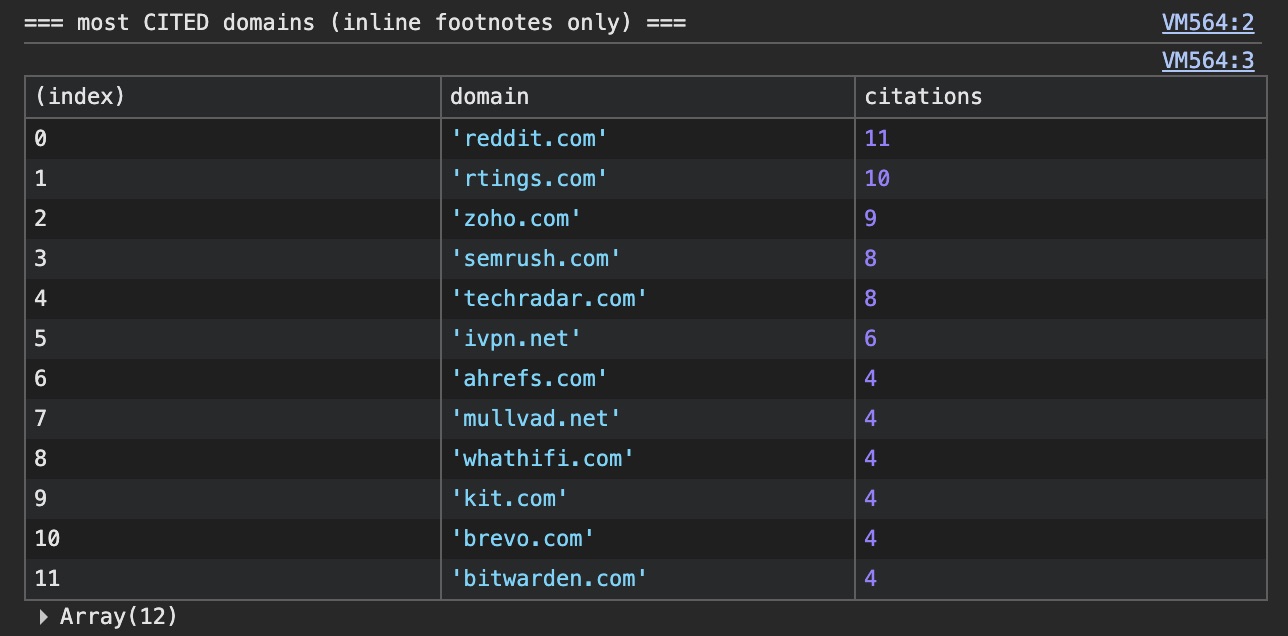
Исследование механизмов поиска ChatGPT выявило четыре основных конвейера получения данных через поле result_source: labrador (лицензированные СМИ вроде Reuters и Wikipedia), bright и oxylabs (коммерческие скрейперы для Reddit и локальных данных), а также serp (стандартная поисковая выдача).
🌍 Появляется понимание механизмов GEO (Generative Engine Optimization). Чтобы бренды оставались источниками цитирования, их данные должны быть доступны в простом HTML-тексте, а не только через динамический JS, иначе нейросети будут опираться на агрегаторы и форумы.
👤 Понимание того, как ChatGPT «выбирает» правду, помогает оптимизировать контент под ИИ-агентов и понимать, почему иногда ответы строятся на основе Reddit, даже если у компании есть официальный сайт.
Источник 1: https://suganthan.com/blog/how-chatgpt-picks-sources/