Исследование работы поисковых механизмов ChatGPT выявило четыре основных конвейера получения данных, которые определяют, на какие ресурсы будет опираться нейросеть при формировании ответов.
Что произошло
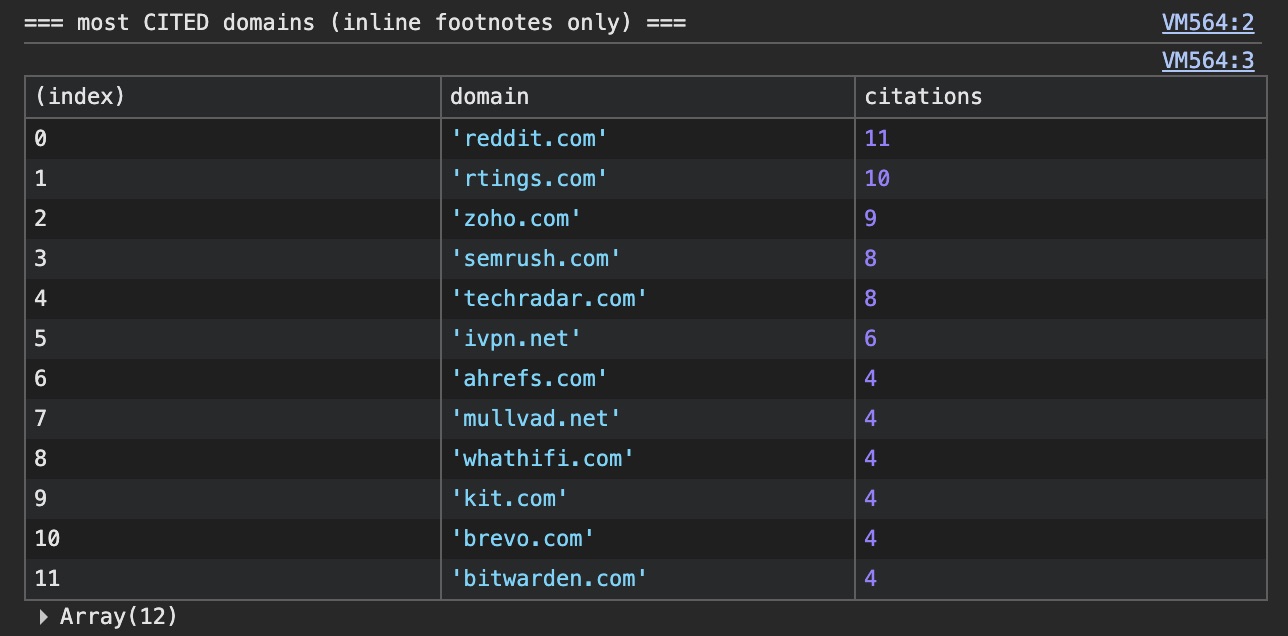
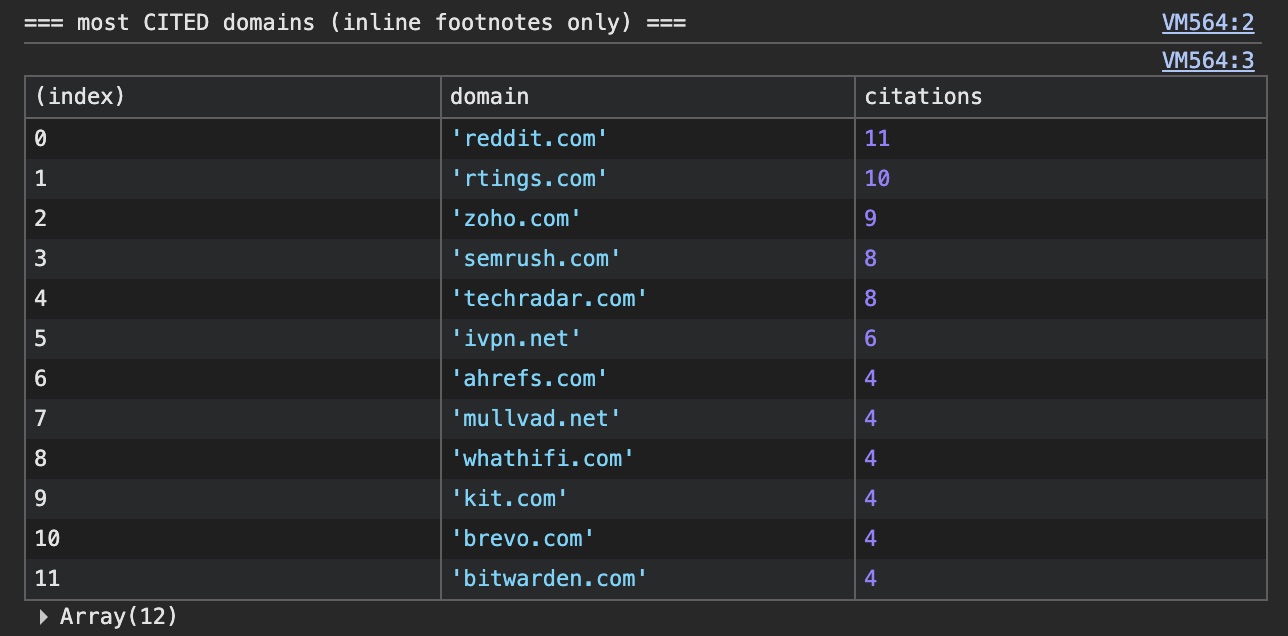
Анализ сетевого трафика ChatGPT показал использование четырех типов конвейеров через поле result_source: labrador (лицензированный контент, например, Wikipedia и Reuters), bright и oxylabs (коммерческие скрейперы для сбора данных с Reddit и локальных ресурсов), а также serp (стандартная поисковая выдача). Процесс включает классификацию интента запроса (text, shopping, thinking) и последующее разбиение задачи на атомарные проверки.
Контекст
Критическим фактором при выборе источника является «читаемость» (readability) данных. Если важная информация, такая как цены или характеристики, скрыта за исполнением сложного JavaScript или требует рендеринга изображений, ChatGPT может проигнорировать официальный сайт компании и использовать данные с агрегаторов или форумов, таких как Reddit.
Почему это важно для индустрии
Для индустрии это знаменует начало эпохи GEO (Generative Engine Optimization). Чтобы бренды оставались первоисточниками для ИИ, их данные должны быть доступны в простом HTML-тексте. Сложная архитектура фронтенда с тяжелым JS может привести к потере цитируемости, вынуждая компании оптимизировать сайты под возможности парсинга LLM-агентов.
Почему это важно для пользователей
Пользователям полезно понимать, почему ответы нейросетей иногда строятся на основе мнений с Reddit, даже если существует официальный сайт продукта. Это знание помогает лучше понимать логику ИИ-агентов и то, как они «выбирают» информацию для предоставления ответов.
Источники
Автор
Look at AI, редакция