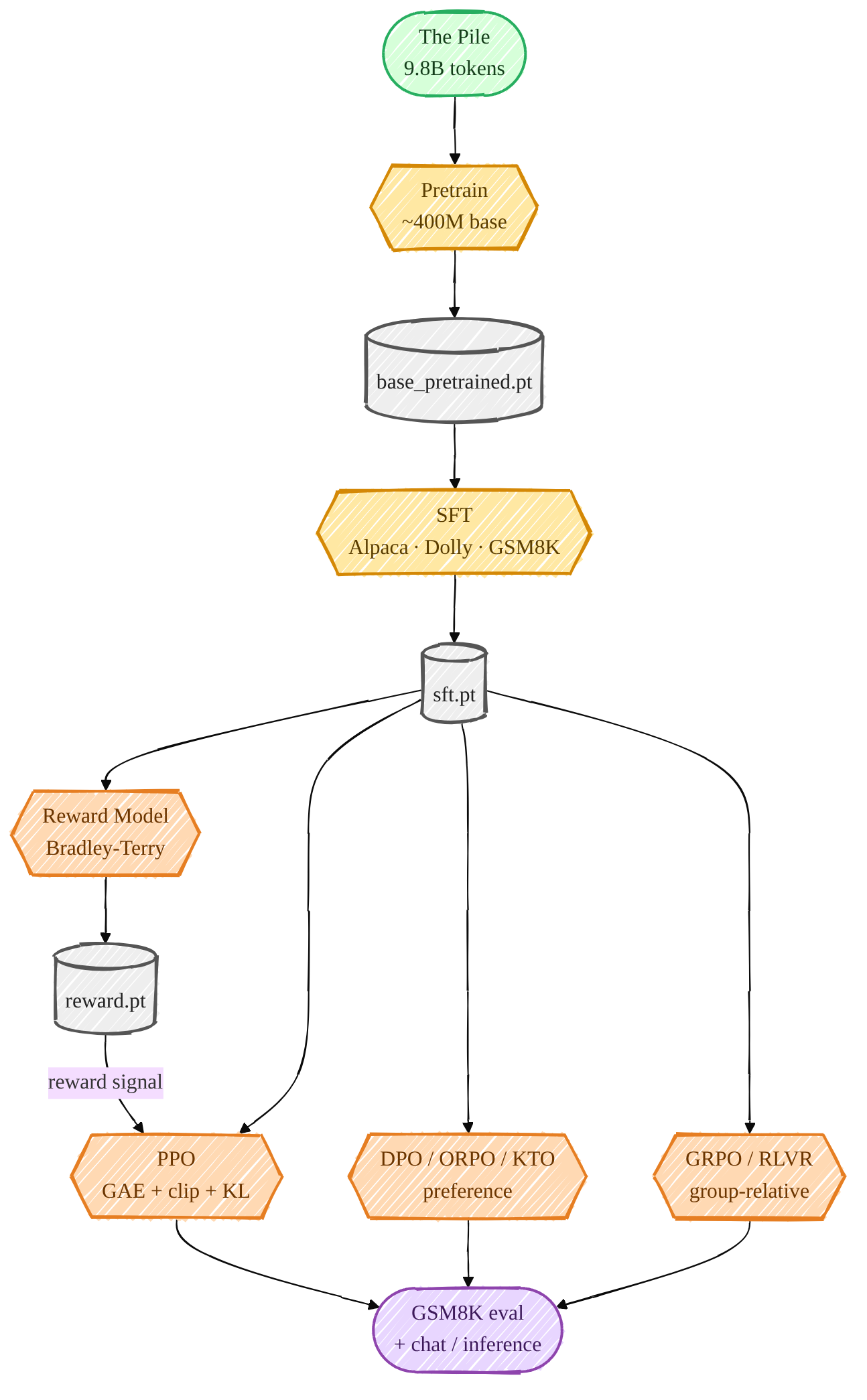
💻 Обучение LLM с нуля на чистом PyTorch
Выпущено техническое руководство по полному циклу создания LLM: от предобучения до выравнивания (alignment). Автор реализует весь пайплайн на чистом PyTorch, намеренно избегая библиотек transformers или trl, чтобы обеспечить глубокое понимание механизмов. Процесс включает этапы SFT, создание Reward Model и использование методов DPO, PPO и GRPO (в стиле DeepSeek-R1).
🌍 Демонстрация того, что современные методы обучения (RLHF, GRPO) могут быть реализованы прозрачно без «черных ящиков» популярных фреймворков, что критически важно для понимания архитектуры и отладки.
👤 Ресурс для тех, кто хочет перейти от использования API к самостоятельному обучению и тонкой настройке моделей, понимая математику и логику каждого этапа.
Источник 1: https://FareedKhan-dev.github.io/train-llm-from-scratch/