Опубликовано подробное техническое руководство по самостоятельному обучению больших языковых моделей (LLM). Процесс охватывает весь жизненный цикл — от этапа предобучения до выравнивания (alignment) — и реализован на чистом PyTorch без использования высокоуровневых библиотек.

Что произошло
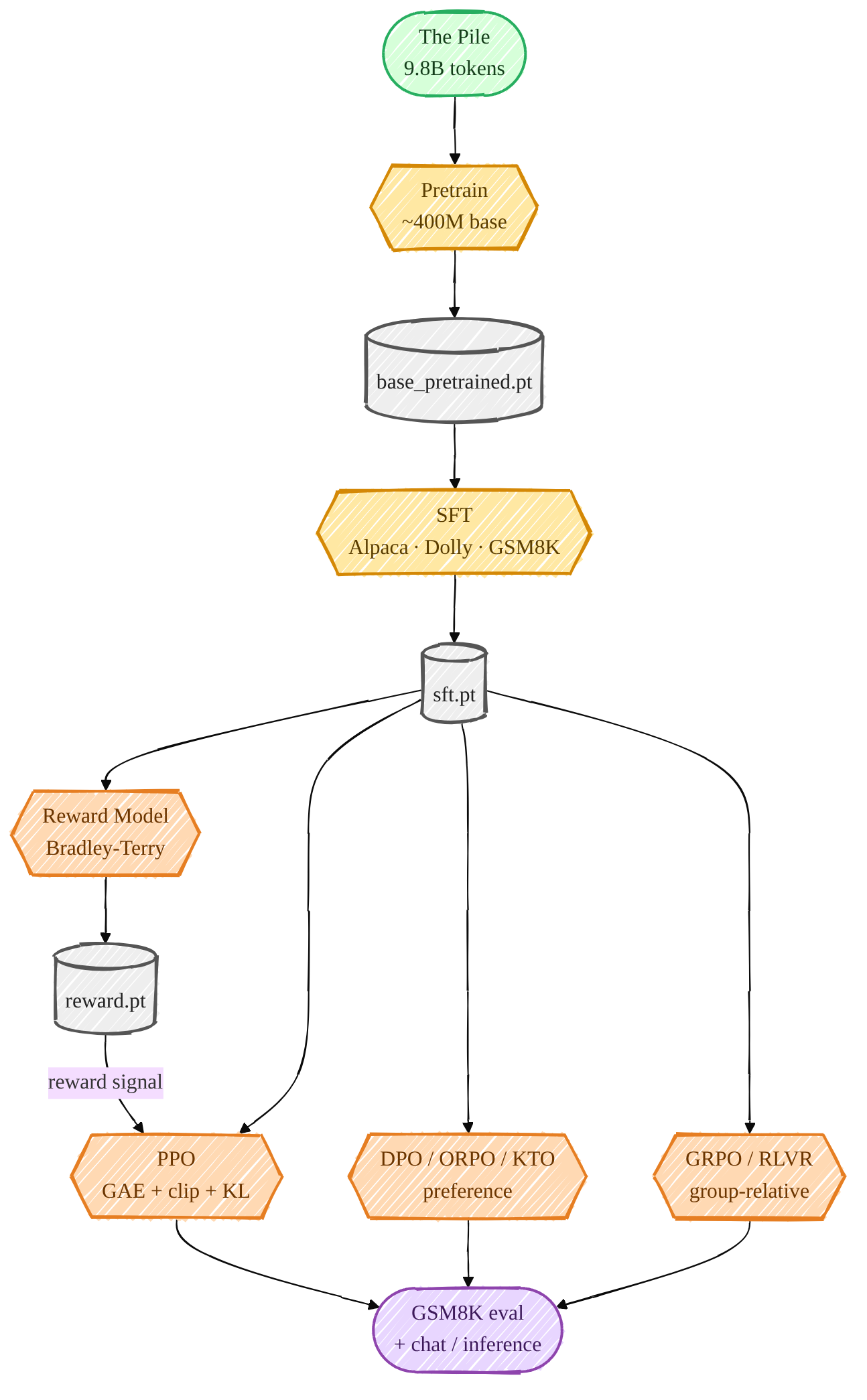
Автор представил комплексный пайплайн обучения, намеренно избегая таких фреймворков, как transformers или trl, для обеспечения максимальной прозрачности. В руководстве подробно разобраны этапы SFT (Supervised Fine-Tuning), создание Reward Model, а также применение методов DPO, PPO и современного подхода GRPO (в стиле DeepSeek-R1) для развития способностей моделей к рассуждению.
Контекст
Использование популярных высокоуровневых библиотек часто создает эффект «черного ящика», скрывая внутренние механизмы работы модели. Переход к реализации на базовом PyTorch позволяет инженерам получить полный контроль над архитектурой и процессами обучения, что критически важно для глубокой отладки и понимания математической логики каждого этапа.
Почему это важно для индустрии
Для индустрии это важный шаг к демонстрации того, что сложные методы обучения, такие как RLHF и GRPO, могут быть реализованы прозрачно. Это снижает зависимость разработчиков от закрытых API и гигантов индустрии, открывая путь к созданию специализированных вертикальных моделей с уникальными методами выравнивания.
Почему это важно для пользователей
Для разработчиков и исследователей это фундаментальный ресурс, позволяющий перейти от разработки простых оберток (wrappers) над готовыми API к созданию глубоких AI-технологий. Руководство помогает освоить математику и логику построения LLM, повышая порог входа в профессиональную работу с моделями.
Что пока неизвестно / ограничения
Несмотря на образовательную ценность, эксперты отмечают, что данный материал является глубоким техническим разбором, а не готовым промышленным решением для немедленной эксплуатации в Enterprise-среде.
Источники
Автор
Look at AI, редакция