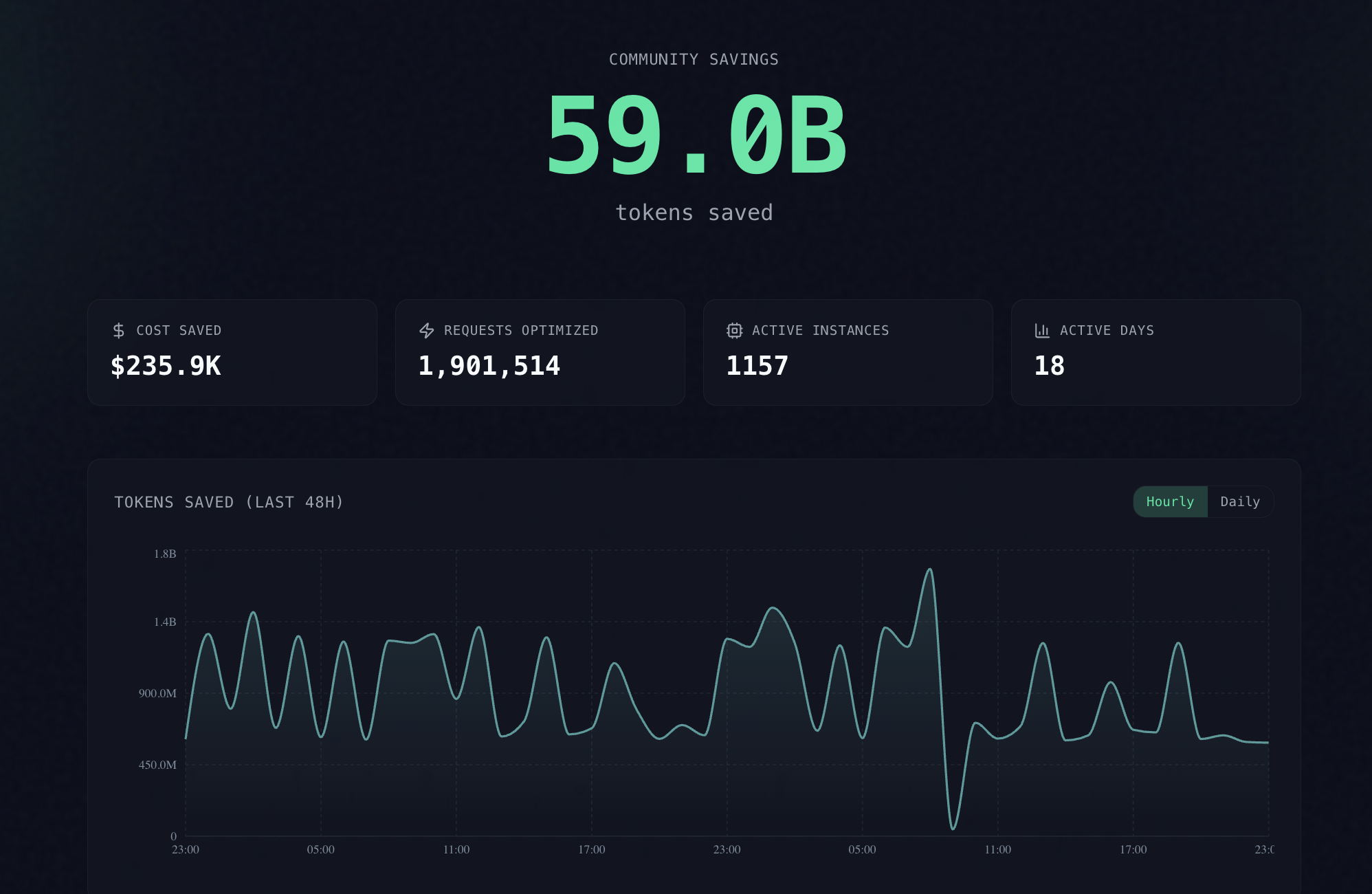
📉 Headroom: экономия до 95% токенов при работе с AI-агентами
Вышел инструмент Headroom для сжатия контекста (логов, файлов, RAG-чанков) перед отправкой в LLM. Технология позволяет сократить расход токенов на 60–95% без потери точности ответов.
🌍 Снижает стоимость (inference cost) и задержки в агентских архитектурах.
👤 Позволяет экономить бюджет на API и быстрее получать ответы от AI-агентов.
Источник 1: https://github.com/chopratejas/headroom