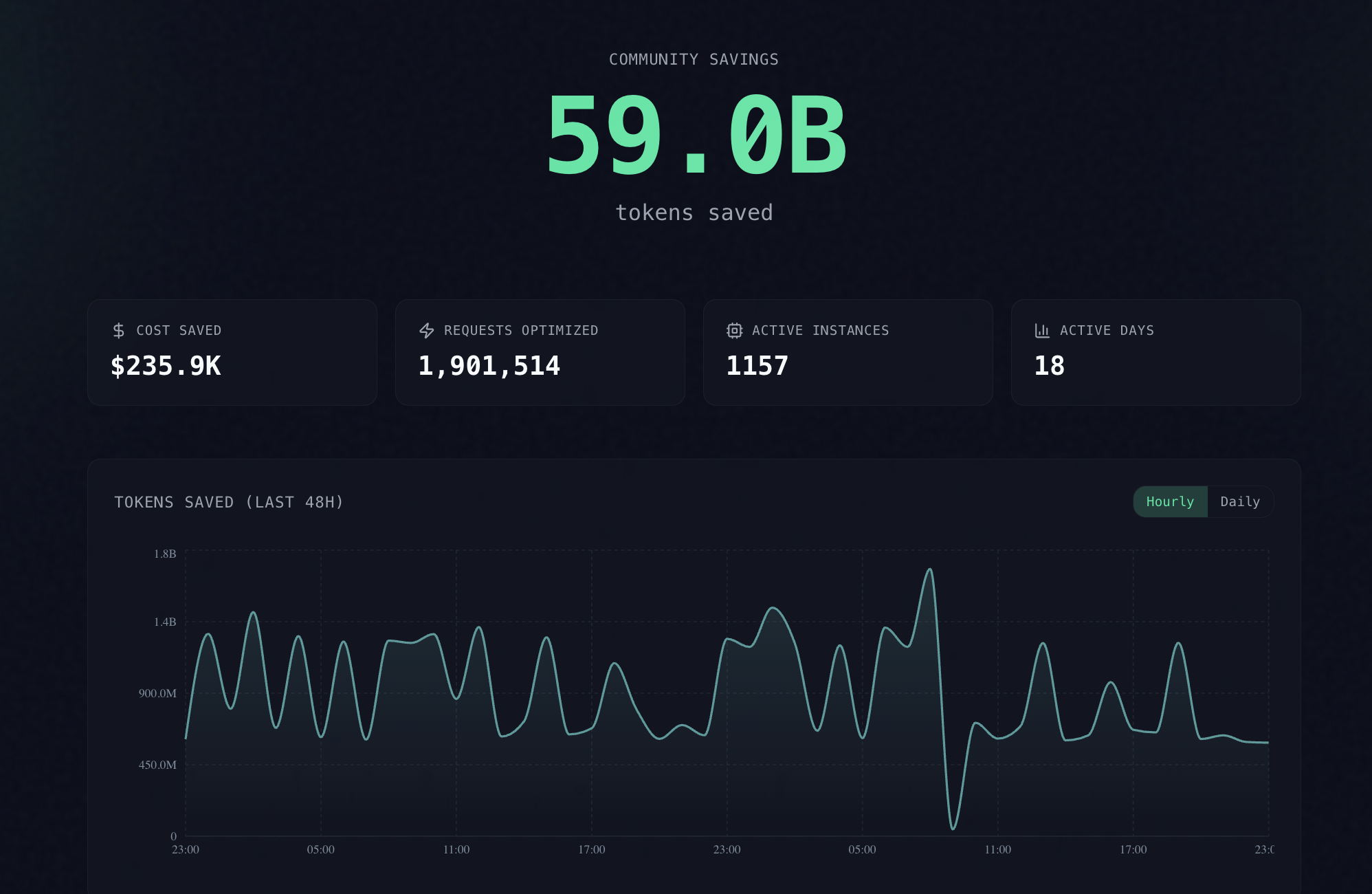
Вышел Headroom — новый инструмент, предназначенный для оптимизации контекста AI-агентов путем сжатия логов, файлов, RAG-чанков и вывода инструментов перед их отправкой в LLM. Технология позволяет сократить расход токенов на 60–95% без существенной потери точности ответов.

Что произошло
Разработчики представили Headroom, инструмент для локального сжатия данных, передаваемых в большие языковые модели. Система использует специализированные алгоритмы: для кода применяется метод AST (Abstract Syntax Tree), для JSON — структурное сжатие, а для обычного текста — модель Kompress-v2-base. Одной из ключевых особенностей является поддержка реверсивного сжатия (CCR), что позволяет восстанавливать оригинальные данные по запросу.
Контекст
В современных агентских архитектурах работа с длинными контекстами требует огромных вычислительных ресурсов и затрат на API. Традиционные методы управления контекстом часто сводятся к простому обрезанию текста (truncation), что ведет к потере важных данных. Headroom предлагает переход к интеллектуальному управлению плотностью информации.
Почему это важно для индустрии
Для индустрии это означает значительное снижение стоимости эксплуатации (inference cost) и уменьшение задержек (latency) при работе с длинными контекстами. Технология напрямую оптимизирует использование KV-кэша провайдеров, повышая общую эффективность инфраструктуры AI-агентов.
Почему это важно для пользователей
Пользователи и разработчики смогут существенно экономить бюджет на API (таких как OpenAI или Anthropic) и быстрее получать ответы от AI-агентов. Инструмент позволяет использовать более длинные контексты в рамках существующих лимитов, не жертвуя качеством работы системы.
Что пока неизвестно / ограничения
Существуют потенциальные риски комплаенса и конфиденциальности при использовании сторонних алгоритмов сжатия, что требует внимания специалистов по защите данных.
Источники
Автор
Look at AI, редакция