
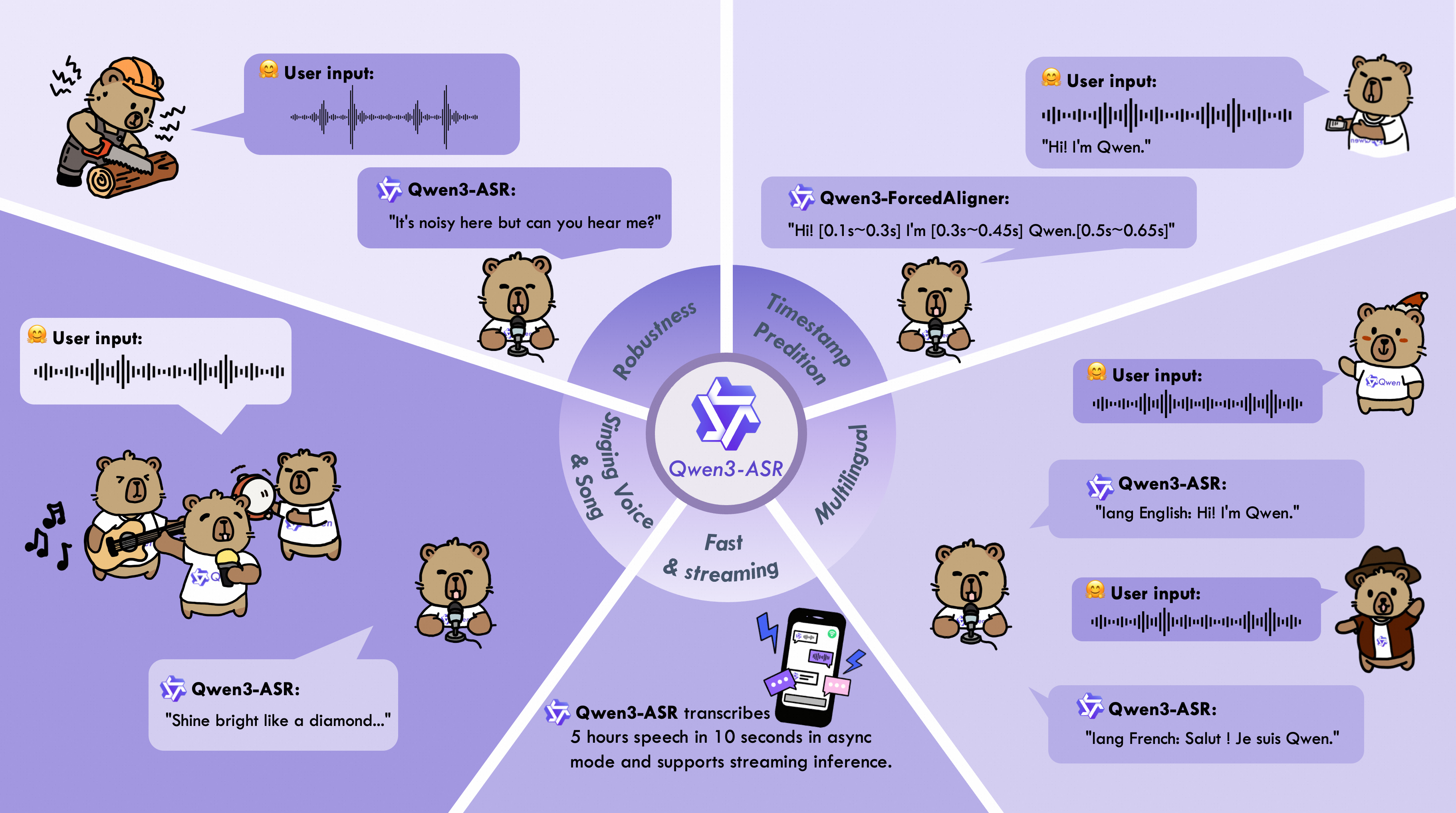
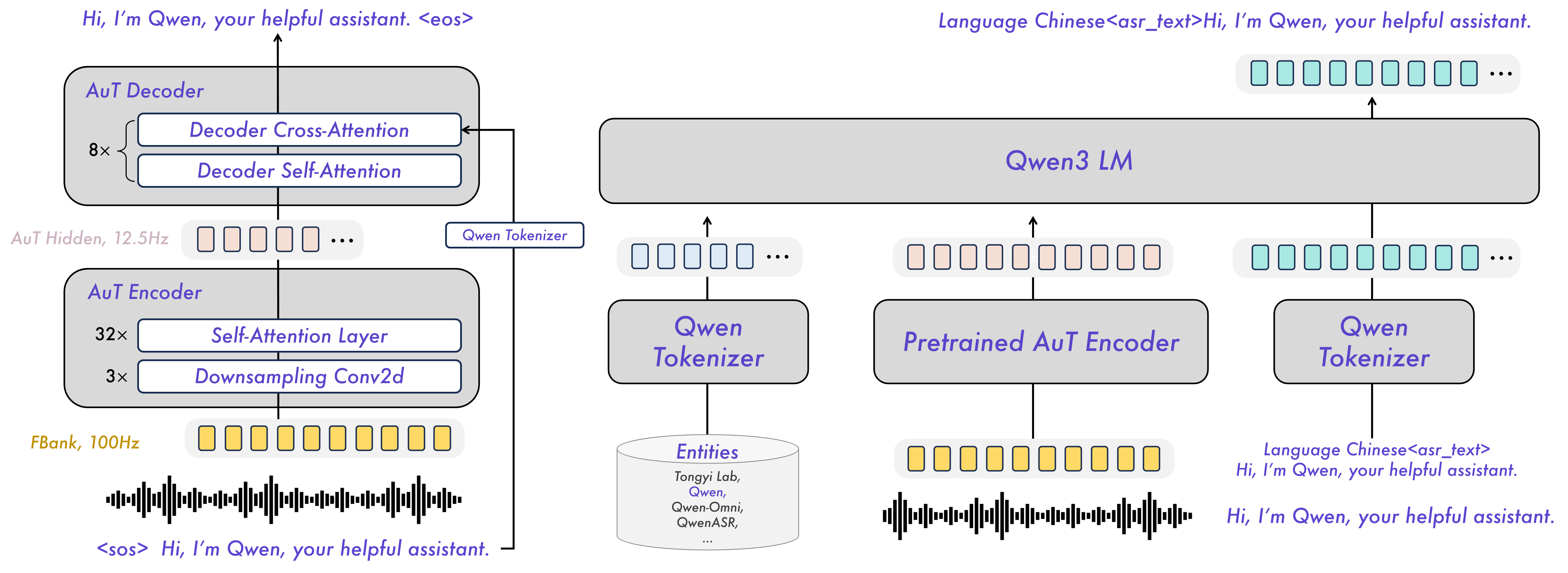
Представлена новая модель Qwen3-ForcedAligner-0.6B-hf, предназначенная для сверхточного выравнивания аудио и текста (forced alignment). Благодаря использованию неавторегрессионного (NAR) режима, модель способна предсказывать таймкоды для слов на 11 языках, включая русский, обеспечивая высокую скорость и точность работы.

Что произошло
Разработчики выпустили модель Qwen3-ForcedAligner-0.6B-hf на базе 0.9B параметров. Инструмент работает в неавторегрессионном (NAR) режиме и оптимизирован через torch.compile для достижения высокой пропускной способности. Модель поддерживает 11 языков и совместима с любыми существующими ASR-системами, позволяя использовать готовые транскрипции для получения идеальных временных меток.
Контекст
Традиционные сквозные (E2E) модели выравнивания часто уступают специализированным методам в скорости или гибкости. Переход к использованию малых LLM (0.6B–0.9B параметров) в неавторегрессионном режиме позволяет разделить задачи распознавания речи и точного позиционирования слов во времени, создавая более эффективные и модульные пайплайны обработки звука.
Почему это важно для индустрии
Для индустрии AI и обработки аудио это означает переход от монолитных E2E-архитектур к стандартизированным слоям alignment. Использование NAR-методов значительно снижает вычислительные затраты и стоимость создания субтитров, а также открывает путь к созданию сверхбыстрых сервисов индексации аудиоконтента для семантического поиска.
Почему это важно для пользователей
Пользователи получают инструмент, который радикально улучшает качество создания субтитров и интерактивных таймкодов в видео. Благодаря возможности интеграции в существующие пайплайны без замены основной ASR-системы, пользователи могут мгновенно повысить точность поиска по звуку и качество текстового сопровождения аудио в любых сервисах.
Источники
Автор
Look at AI, редакция