Компания Liquid AI представила новые мультиязычные retrieval-модели LFM2.5-Embedding-350M и LFM2.5-ColBERT-350M, которые демонстрируют исключительную скорость и эффективность в задачах поиска.
Что произошло
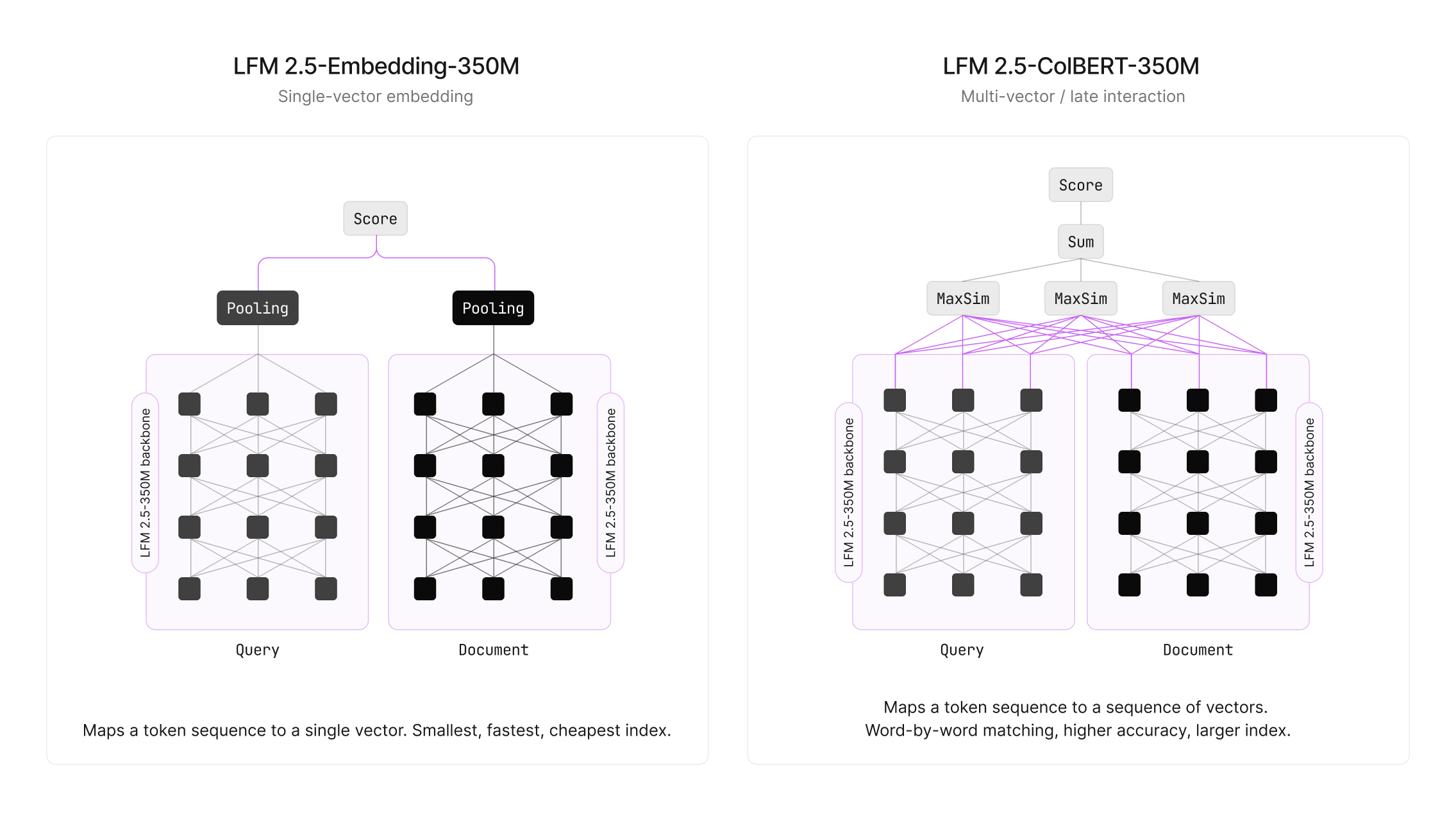
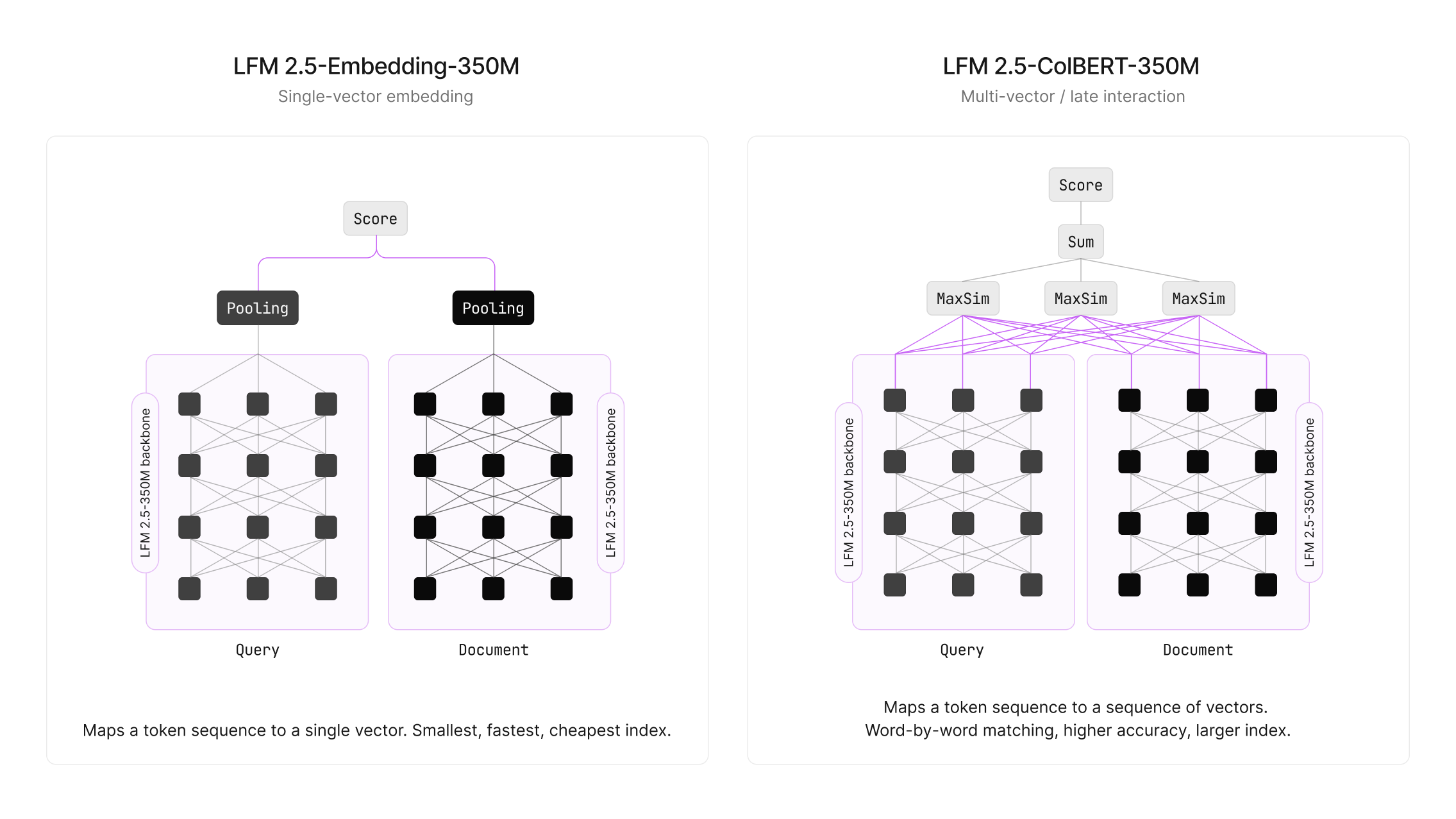
Liquid AI выпустила две компактные модели на 350 млн параметров: LFM2.5-Embedding-350M и LFM2.5-ColBERT-350M. Это первые двунаправленные модели в семействе LFM, созданные путем модификации архитектуры LFM2.5-350M-Base (удаление причинной маски и переход к симметричным свёрткам). Модели поддерживают 11 языков. На оборудовании H100 задержка ColBERT составляет около 2.5 мс (p50), а на MacBook M4 Max — около 7-8 мс (p50).
Контекст
Архитектурный сдвиг заключается в переходе от causal decoder к bidirectional encoder. Использование симметричных свёрток вместо причинной маски позволяет моделям использовать контекст в обоих направлениях, что критически важно для качества эмбеддингов. При этом модель ColBERT (0.605 NDCG@10 на NanoBEIR) превосходит существующие решения, такие как Qwen3-Embedding-0.6B (0.556) и gte-multilingual-base (0.528), несмотря на меньшее количество параметров.
Почему это важно для индустрии
Появление эффективных и компактных двунаправленных энкодеров позволяет значительно снизить стоимость и задержки при развертывании RAG-систем и поисковых движков. Это открывает путь к созданию высокопроизводительных edge-решений и снижению зависимости от тяжелых облачных API и массивных моделей в мультиязычной среде.
Почему это важно для пользователей
Пользователи получают возможность запускать качественный поиск и системы ответов на вопросы (FAQ) локально на мощных ноутбуках или на недорогом оборудовании с очень высокой скоростью отклика, обеспечивая при этом высокий уровень приватности данных.
Источники
Автор
Look at AI, редакция