
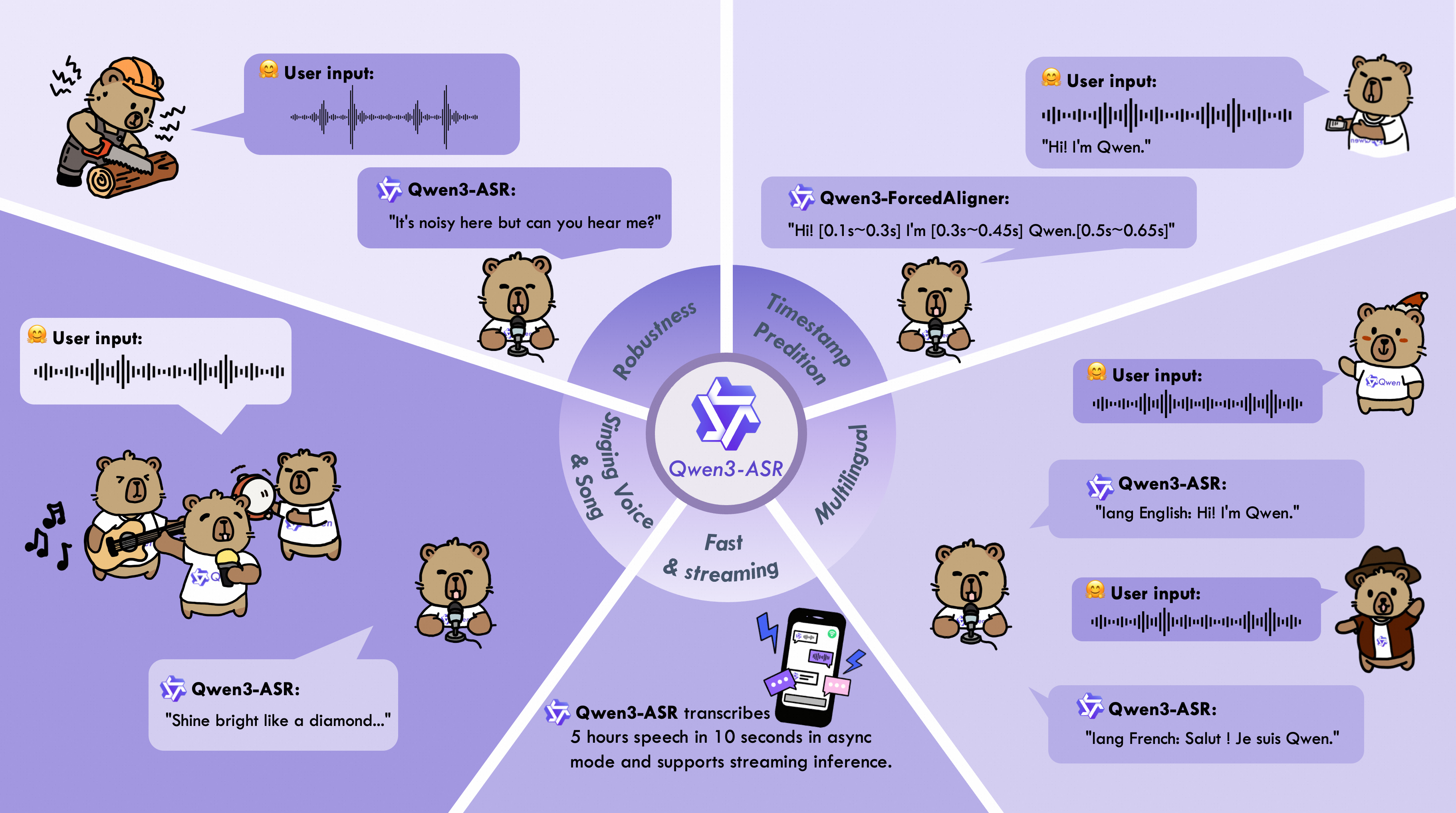
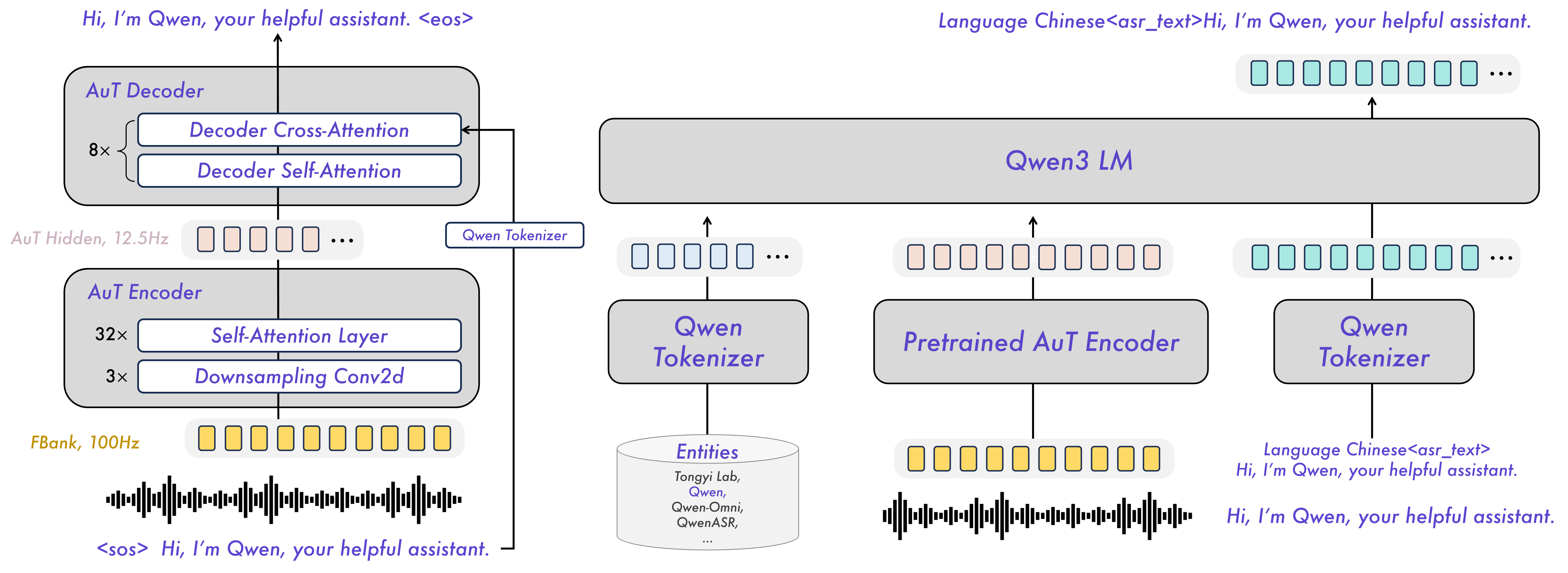
A new model, Qwen3-ForcedAligner-0.6B-hf, has been introduced, designed for ultra-precise audio and text alignment (forced alignment). By using a non-autoregressive (NAR) mode, the model is capable of predicting timecodes for words in 11 languages, including Russian, ensuring high speed and accuracy.

What Happened
Developers have released the Qwen3-ForcedAligner-0.6B-hf model based on 0.9B parameters. The tool operates in non-autoregressive (NAR) mode and is optimized via torch.compile to achieve high throughput. The model supports 11 languages and is compatible with any existing ASR systems, allowing the use of ready-made transcriptions to obtain perfect timestamps.
Context
Traditional end-to-end (E2E) alignment models often fall short of specialized methods in terms of speed or flexibility. Moving toward the use of small LLMs (0.6B–0.9B parameters) in non-autoregressive mode allows for the separation of speech recognition tasks from precise temporal word positioning, creating more efficient and modular audio processing pipelines.
Why It Matters for the Industry
For the AI and audio processing industry, this signifies a shift from monolithic E2E architectures to standardized alignment layers. The use of NAR methods significantly reduces computational costs and the expense of subtitle creation, while also paving the way for ultra-fast audio content indexing services for semantic search.
Why It Matters for Users
Users gain a tool that radically improves the quality of subtitle creation and interactive video timecodes. Thanks to its ability to integrate into existing pipelines without replacing the primary ASR system, users can instantly increase audio search accuracy and the quality of text accompaniment for audio in any service.
Sources
Author
Look at AI, Editorial Staff