
A video report by Ibragim Badertdinov from Nebius at the AI Engineer Europe conference has been published, focusing on the SWE-rebench system. This dynamic benchmark allows for an objective evaluation of AI agent capabilities by solving real GitHub issues and preventing data leakage through monthly task set updates.


What Happened
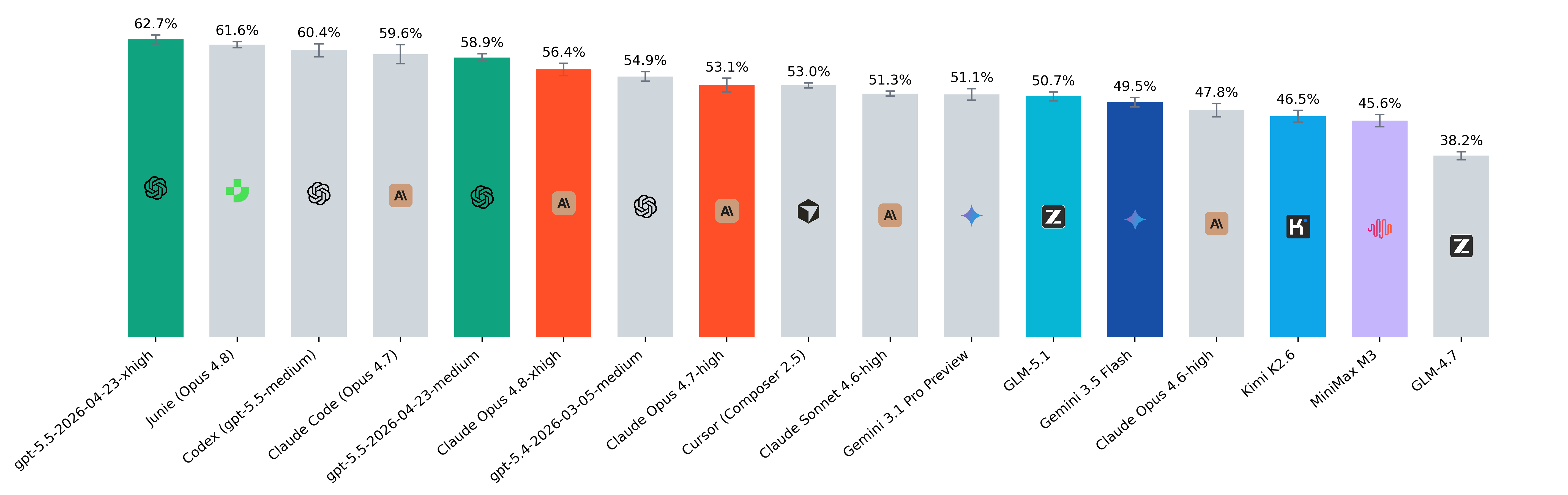
The report presents the SWE-rebench system, which utilizes a time-splitting approach for model evaluation. In the current rankings, the gpt-5.5 and Junie models lead with a Resolved Rate of over 60%, while solving tasks via Cursor demonstrates the highest economic efficiency, costing $0.23 per task.
Context
Traditional static benchmarks quickly lose relevance due to contamination—where test tasks end up in model training datasets. SWE-rebench addresses this problem by offering dynamic task updates, allowing for a distinction between models that simply "remember" ready-made solutions and systems capable of actually using tools like git, curl, and file editors.
Why It Matters for the Industry
For the industry, the shift toward dynamic benchmarks necessitates the development of infrastructure to run thousands of isolated sandboxes. This is becoming a prerequisite for creating the high-quality data required for Reinforcement Learning (RL) cycles, where agents are trained based on the results of passing such verifiable tests.
Why It Matters for Users
For developers and users, SWE-rebench serves as a reliable tool for comparing AI coders in real-world scenarios rather than on abstract tests. The emergence of new metrics, such as Resolved Rate and cost-efficiency, helps in making more informed choices regarding development tools like Cursor or specialized models.
What Is Not Yet Known / Limitations
While technical and economic efficiency are evaluated in detail, questions regarding legal risks related to intellectual property and the regulatory status of such systems remain less explored within this technical comparison.
Sources
- SWE-rebench: Lessons from Evaluating Coding Agents — Ibragim Badertdinov, Nebius
- SWE-rebench Leaderboard
Author
Look at AI, Editorial Staff