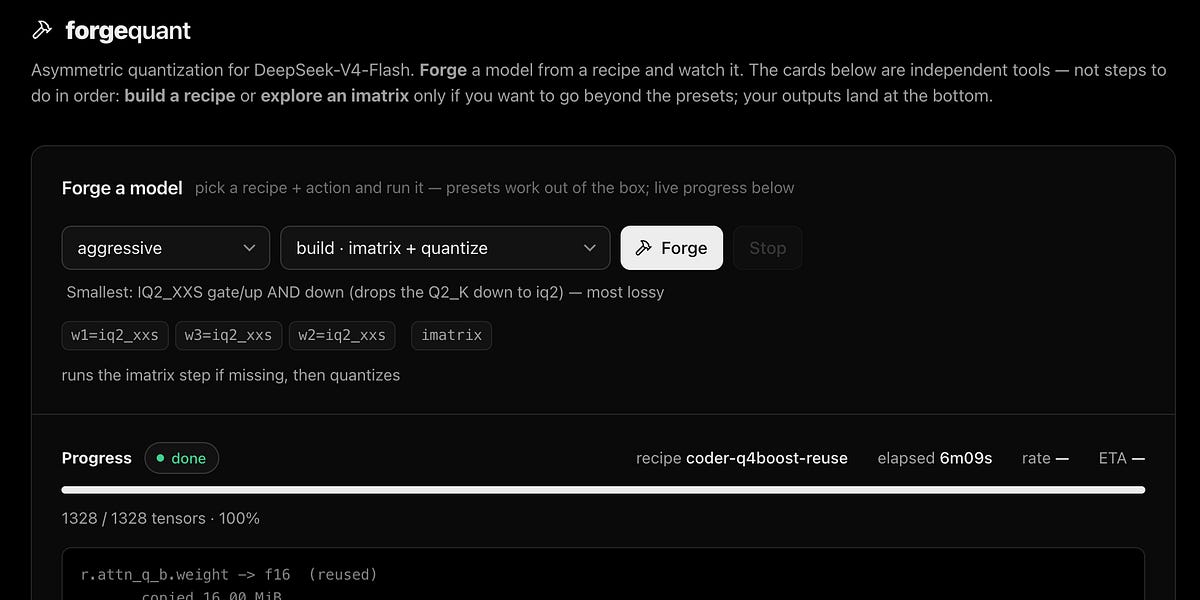
A new method for incremental quantization of local LLMs has been developed, reducing the time required to rebuild model variants from 80 minutes to approximately 5 minutes. The technology uses hash comparisons (fingerprints) to skip unchanged tensors, radically accelerating the process of finding optimal parameters.
What Happened
Developers have introduced an incremental quantization technology that speeds up the optimization process of local language models by 14 times. Instead of a full rebuild of weights, the system identifies unchanged parts of the model through hashing and works only with the modified tensors. This reduces the iteration cycle from 80 minutes to about 5 minutes.
Context
When quantizing models for local hardware, it is often necessary to find a balance between model size and quality (bit-width). The traditional approach requires a full processing cycle for every parameter change, which takes significant time. The new method allows for granular quantization (mixed-precision)—for example, maintaining high precision (8-bit) for critical router layers while applying aggressive compression (2-bit) for experts in MoE (Mixture of Experts) architectures.
Why It Matters for the Industry
This method significantly accelerates the development and prototyping cycle for optimized models, making the creation of customized Edge AI solutions more accessible. In the long term, this could lead to the integration of incremental quantization into tools like llama.cpp or AutoGPTQ, and the development of self-adaptive quantization concepts, where a model dynamically changes its precision based on available computational resources.
Why It Matters for Users
The process of finding the optimal model version that fits into VRAM without significant quality loss will become orders of magnitude faster. This makes deep fine-tuning of neural networks for specific home hardware accessible even to users without professional computing power, turning a multi-hour task into a minute-long one.
What Is Not Yet Known / Limitations
Current discussions focus on development speed and optimization, without paying sufficient attention to potential operational risks when using new compression methods.
Sources
Author
Look at AI, Editorial Team