The OpenMOSS team has introduced MOSS-Video-Preview — a new multimodal foundation model capable of analyzing video streams in real-time with extremely low latency.


What Happened
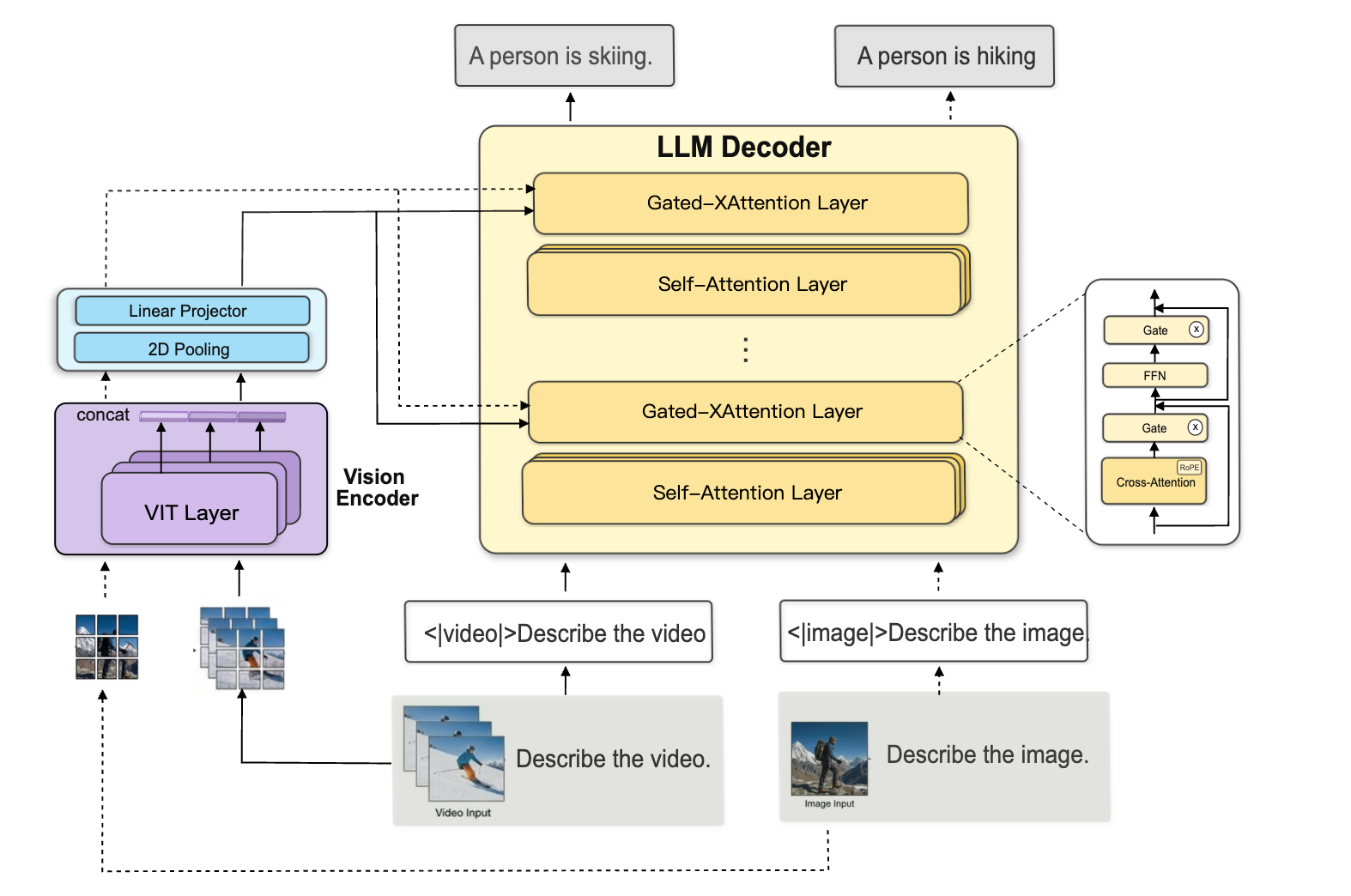
Developed based on the Llama-3.2-Vision architecture, the MOSS-Video-Preview model, with approximately 11 billion parameters, supports streaming inference. A key technical feature is the use of a gated cross-attention mechanism, which allows for the efficient separation of visual and linguistic features during data processing.
Context
Unlike traditional methods that rely on batch processing of video clips, this solution aims for native stream understanding. This allows the model to react to changes in the visual context almost instantaneously, avoiding delays associated with the need to buffer entire video files or large segments.
Why It Matters for the Industry
For the AI industry, the transition from batch analysis to native real-time understanding via cross-attention architecture paves the way for creating truly interactive AI assistants. The use of open weights and code provides a powerful tool for rapid prototyping of next-generation Video Language Models (VLM).
Why It Matters for Users
For end users, this means the emergence of technologies capable of "seeing" and conversing about live events—for example, in video calls or streams—providing full interaction with the visual context with almost no latency.
What Is Not Yet Known / Limitations
Questions remain regarding the security of streaming data and latency management, which are critical for deploying this technology in production environments.
Sources
- GitHub - OpenMOSS/MOSS-Video-Preview
- MOSS-Video-Preview Collection on Hugging Face
- MOSS-Video-Preview: Toward Real-Time Video Understanding via Cross-Attention (arXiv)
Author
Look at AI, Editorial Staff