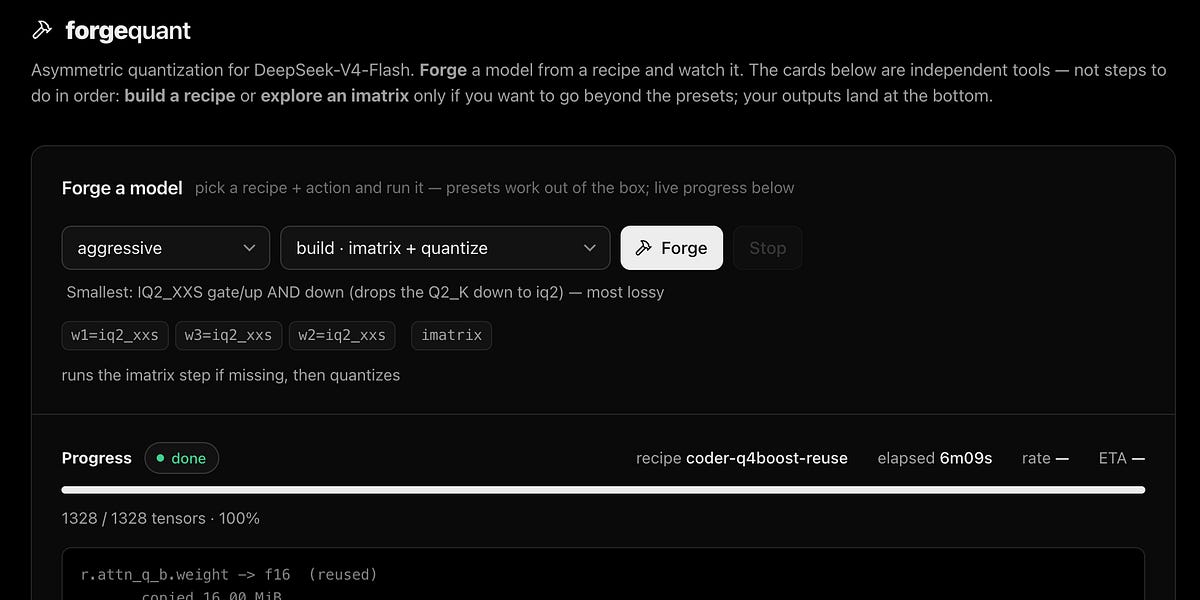
🚀 LLM Quantization Accelerated 14x
A method for incremental quantization of local LLMs has been developed, reducing model rebuild times from 80 to 5 minutes. The technology uses tensor hash comparisons (fingerprints), allowing unchanged parts to be skipped during the rebuild process.
🌍 The method accelerates the optimization cycle for local models, enabling developers to quickly find the balance between quality and size for specific tasks.
👤 The process of selecting model parameters for consumer hardware will become much faster, eliminating hours of waiting after every adjustment.
Source 1: https://andreaborio.substack.com/p/re-quantizing-a-local-model-14-faster