🚀 Обучение LLM через RL на чистом CUDA
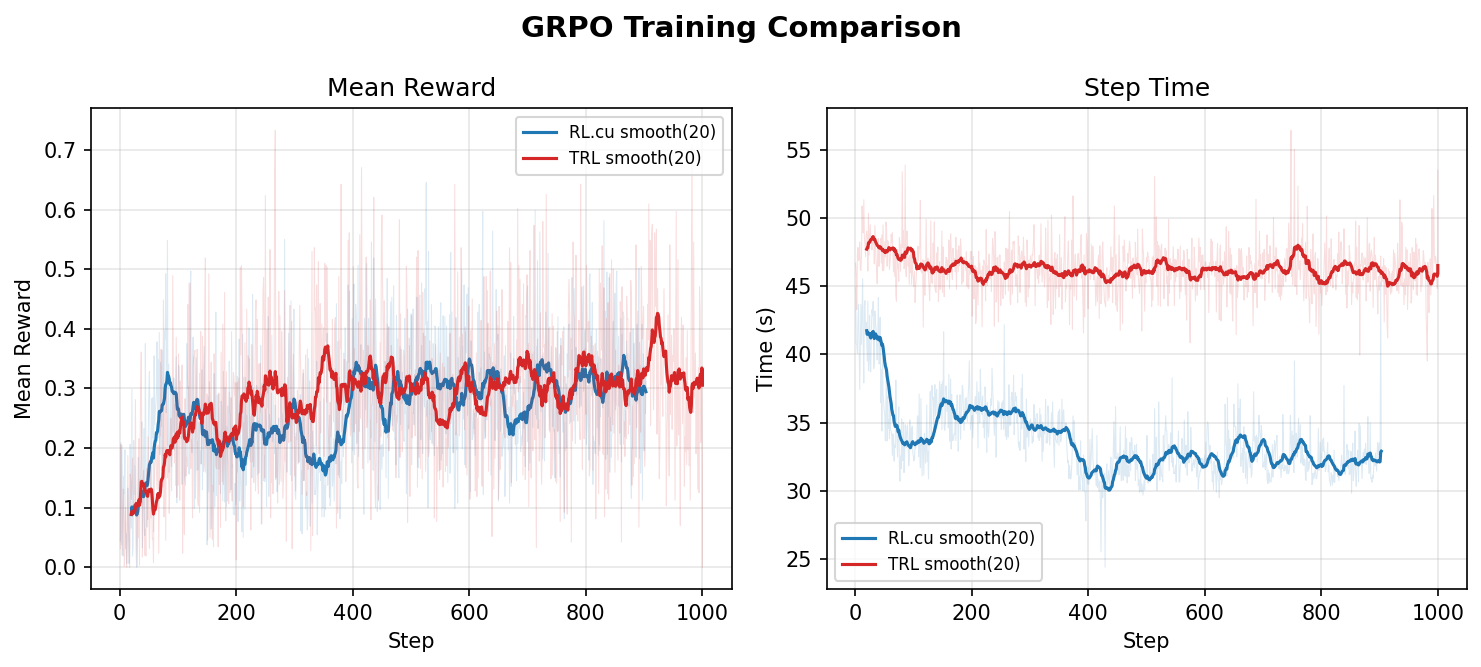
Представлен проект RL.cu, позволяющий проводить полный цикл обучения с подкреплением (SFT + GRPO) на чистом CUDA/C++ без зависимости от PyTorch. Система включает hand-written ядра (FlashAttention-2, RMSNorm, RoPE, AdamW) и движок с continuous batching и Paged KV cache. Тесты на Qwen3-0.6B показали ускорение в 1.37 раза по сравнению со стеком TRL + vLLM.
🌍 Проект устраняет разрыв между фазами обучения и инференса (train-inference mismatch), позволяя использовать единые веса и процессы, что радикально снижает оверхед и зависимость от тяжелых библиотек.
👤 Разработчики получают инструмент для максимально эффективного использования GPU, минимизируя задержки на управление памятью и передачу данных.
Источник 1: https://github.com/KJLdefeated/RL.cu