Разработчик представил проект RL.cu — систему для обучения больших языковых моделей (LLM) методу обучения с подкреплением (RL) с использованием исключительно CUDA и C++. Проект позволяет реализовать полный цикл обучения без зависимости от тяжеловесного фреймворка PyTorch, значительно повышая эффективность использования GPU.


Что произошло
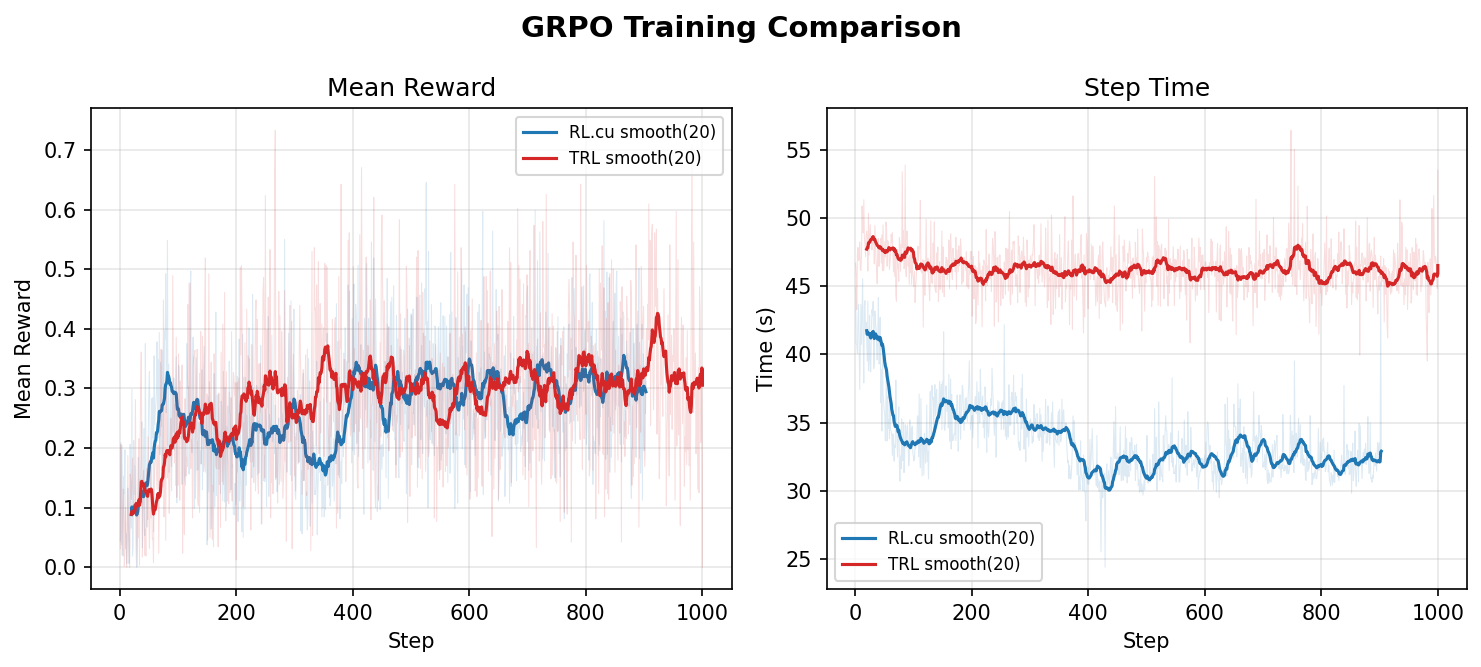
Был представлен open-source проект RL.cu, который реализует полный цикл Reinforcement Learning (SFT + GRPO) на чистом CUDA/C++. Система включает в себя hand-written ядра (FlashAttention-2, RMSNorm, RoPE, AdamW) и специализированный движок инференса с поддержкой continuous batching и Paged KV cache. Согласно бенчмаркам на модели Qwen3-0.6B, решение обеспечивает ускорение обучения в 1.37 раза по времени (wall-clock) по сравнению со стандартным стеком TRL + vLLM при сохранении сопоставимого уровня вознаграждения (reward).
Контекст
Современные процессы RL-обучения LLM обычно опираются на высокоуровневые библиотеки вроде PyTorch, что создает разрыв (train-inference mismatch) между фазами обучения и инференса. Использование единого процесса и общих весов в RL.cu позволяет устранить этот разрыв и снизить накладные расходы на управление памятью и передачу данных.
Почему это важно для индустрии
Проект демонстрирует возможность перехода к вертикально интегрированным, 'bare-metal' стекам обучения. Это открывает путь к созданию сверхэффективных и легковесных систем, которые могут радикально снизить операционные расходы на обучение моделей и устранить зависимость от универсальных, но тяжеловесных фреймворков.
Почему это важно для пользователей
Разработчики и исследователи получают инструмент для максимально производительного и дешевого проведения RL-экспериментов (SFT + GRPO) на имеющемся оборудовании, минимизируя задержки и упрощая стек зависимостей при работе с малым и средним размером моделей.
Что пока неизвестно / ограничения
Существуют риски, связанные со сложностью поддержки и обеспечения безопасности при отказе от проверенных индустриальных стандартов, таких как PyTorch.
Источники
Автор
Look at AI, редакция