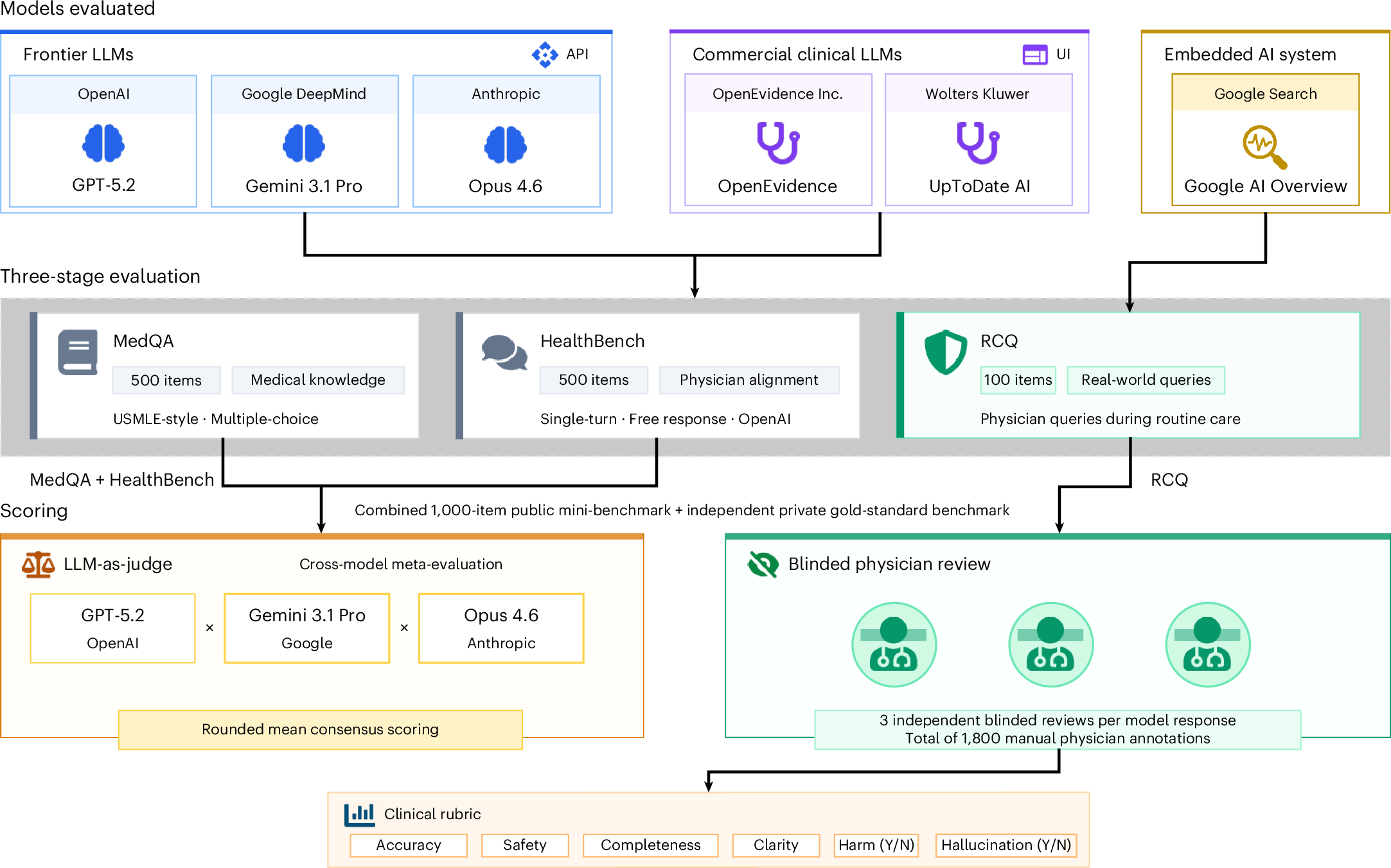
🩺 Универсальные LLM превзошли медицинские ИИ
Исследование в Nature Medicine показало, что универсальные модели (Gemini 3.1 Pro, Claude Opus 4.6) превосходят специализированные инструменты (OpenEvidence, UpToDate Expert AI) в тестах на медицинские знания. В тесте MedQA Gemini 3.1 Pro набрал 97.4%, против 89.6% у OpenEvidence.
🌍 Это ставит под сомнение эффективность текущих узкоспециализированных RAG-систем и может изменить стратегии разработки медицинского ПО и закупки ИИ-решений.
👤 Не стоит слепо доверять приложениям с пометкой «медицинский AI» — топовый чат-бот может оказаться более точным помощником.
Источник 1: https://www.nature.com/articles/s41591-026-04431-5