
Компания Unstract представила специализированную архитектуру на базе шести агентов для решения одной из самых сложных задач Document AI — точного извлечения данных из неструктурированных PDF-таблиц.
Что произошло
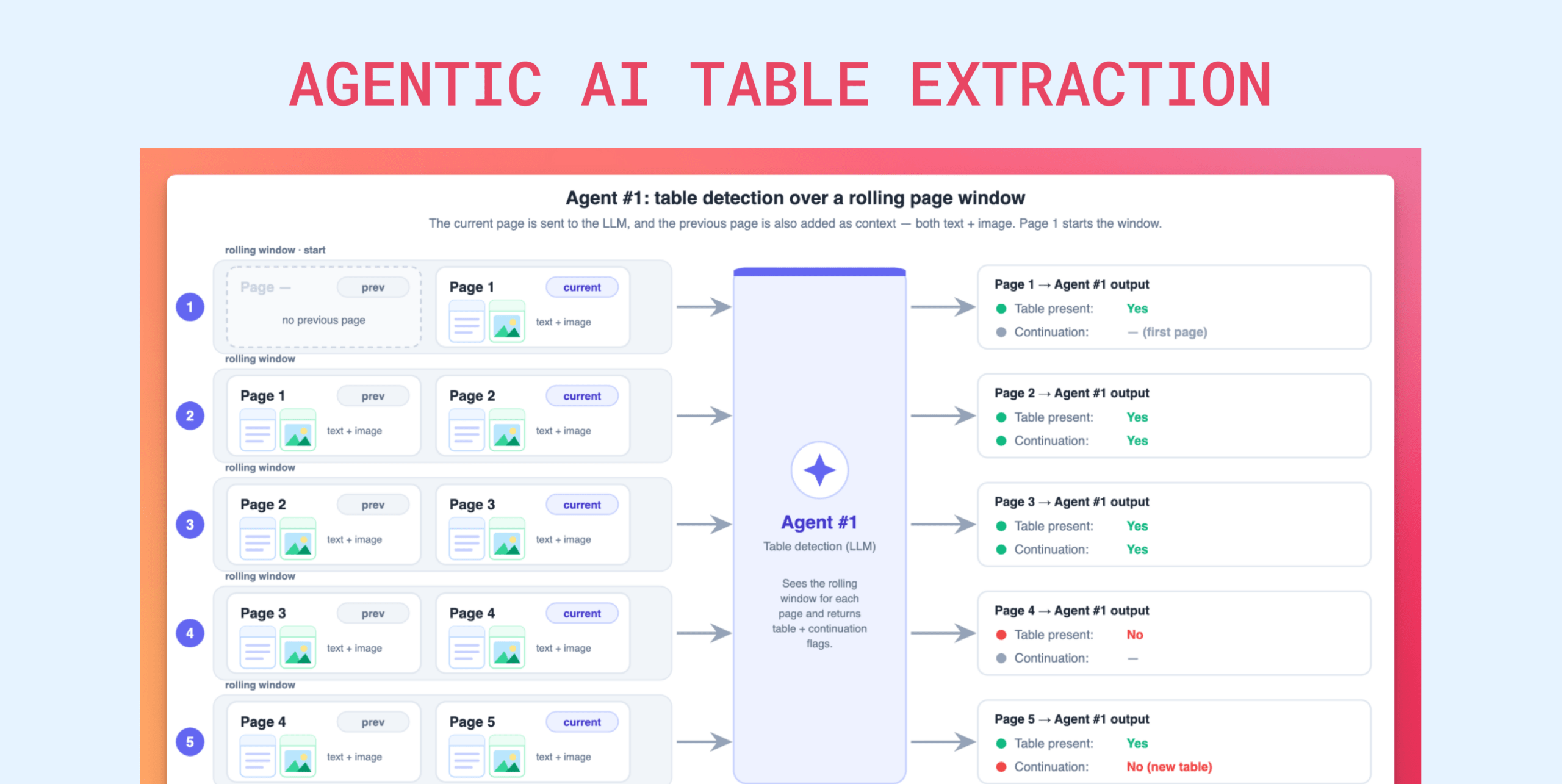
Вместо использования одного универсального LLM-агента, Unstract внедрила конвейер (pipeline), где задачи разделены между специализированными ролями. Система выполняет детектирование таблиц, генерацию промптов и, что критически важно, автоматическую генерацию Python-скриптов (Codegen) для финального маппинга данных в целевую JSON-схему.
Контекст
Традиционные подходы с использованием монолитных LLM-запросов часто сталкиваются с галлюцинациями, высокими затратами на токены и ограничениями на длину контекста при работе со сложными документами. Проблема «кривых» таблиц в PDF долгое время оставалась ахиллесовой пятой систем RAG.
Почему это важно для индустрии
Этот подход знаменует переход от простых LLM-запросов к полноценным Agentic Workflows. Для индустрии это означает возможность создания масштабируемых и надежных ETL-инструментов, где AI выступает не просто как чат-бот, а как планировщик и кодер, интегрированный с классическим программным обеспечением.
Почему это важно для пользователей
Для разработчиков и бизнеса это практический пример того, как разделение ролей между маленькими и большими моделями в сочетании с генерацией кода делает работу с AI более предсказуемой, дешевой и пригодной для промышленной эксплуатации.
Что пока неизвестно / ограничения
Существуют потенциальные юридические риски, связанные с безопасностью исполнения автоматически сгенерированного кода в производственных средах.
Источники
Автор
Look at AI, редакция