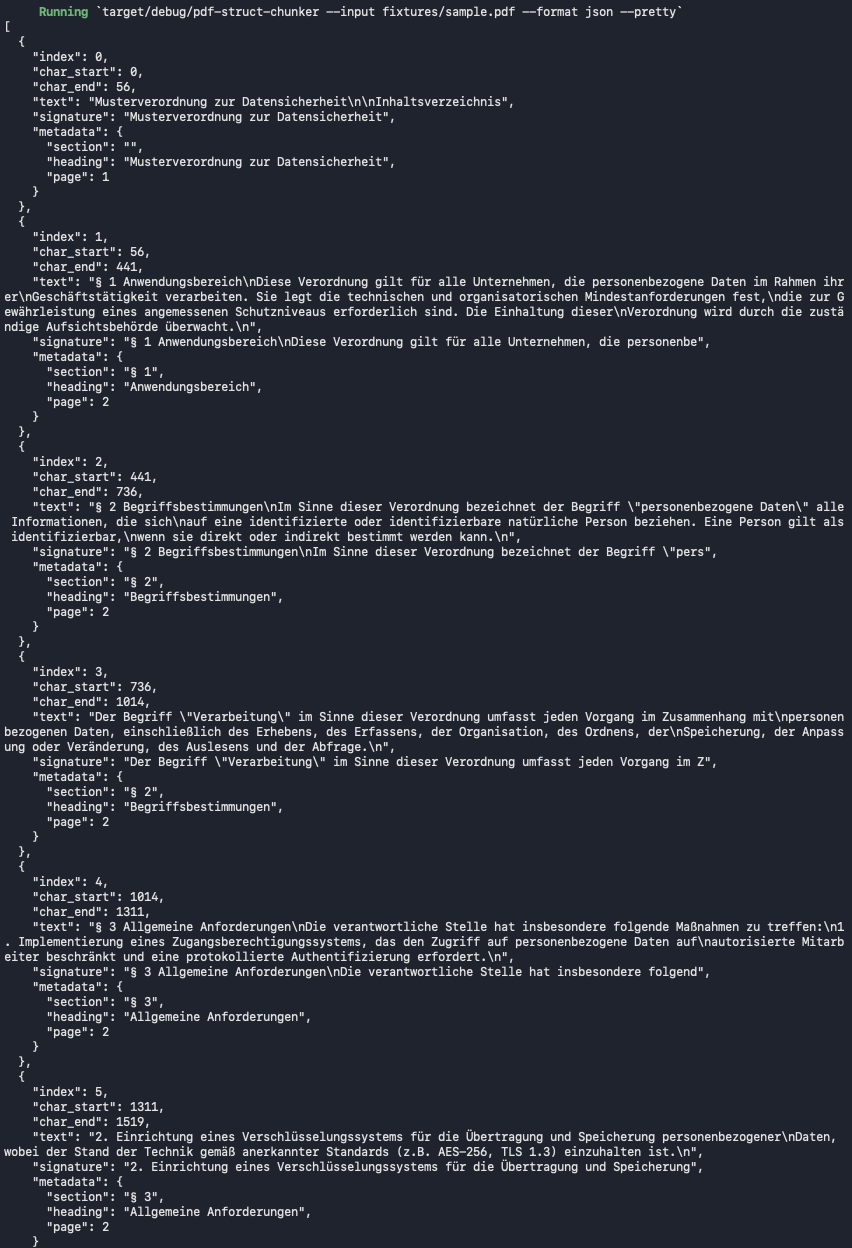
Разработчики представили pdf-struct-chunker — новый инструмент на языке Rust, который позволяет семантически разбивать PDF-документы на фрагменты без использования LLM. Благодаря анализу макета документа, библиотека сохраняет иерархическую структуру заголовков и параграфов, обеспечивая высокую точность подготовки данных для RAG-систем.

Что произошло
Опубликован open-source проект pdf-struct-chunker, предназначенный для интеллектуального сегментирования PDF-файлов. Инструмент использует анализ визуальных метаданных, таких как координаты X/Y, размеры шрифтов и начертание текста, вместо традиционного разбиения по количеству токенов или символов. Реализация на Rust позволяет обрабатывать 100 страниц менее чем за одну секунду при минимальном потреблении памяти.
Контекст
В современных RAG-системах (Retrieval-Augmented Generation) стандартные методы «наивного» разбиения текста часто приводят к разрыву смысловых блоков, что провоцирует галлюцинации нейросетей. Существующие альтернативы, использующие LLM для структурирования документов, являются крайне ресурсоемкими и дорогими, что создает барьер для масштабирования и использования в Edge-AI решениях.
Почему это важно для индустрии
Для индустрии этот инструмент переводит обработку структуры документа из категории дорогостоящих задач для нейросетей в категорию дешевых инфраструктурных процессов. Он позволяет существенно повысить качество индексации в RAG-стеках без дополнительных затрат на GPU и снижает совокупную стоимость владения (TCO) корпоративными ИИ-решениями за счет оптимизации этапа препроцессинга.
Почему это важно для пользователей
Разработчики поисковых систем на базе ИИ и специалисты по работе с большими данными получают возможность избежать потери контекста при извлечении информации из документов. Использование layout-aware подхода позволяет передавать в векторные базы данных структурно целостные фрагменты с метаданными, что напрямую снижает риск получения неверных ответов от модели.
Источники
Автор
Look at AI, редакция