
Новое исследование эффективности малых языковых моделей (менее 1B параметров) на платформе NVIDIA Jetson Orin Nano Super 8GB показало, что правильная настройка режима питания и выбор специализированного бэкенда позволяют значительно повысить производительность edge-вычислений.

Что произошло
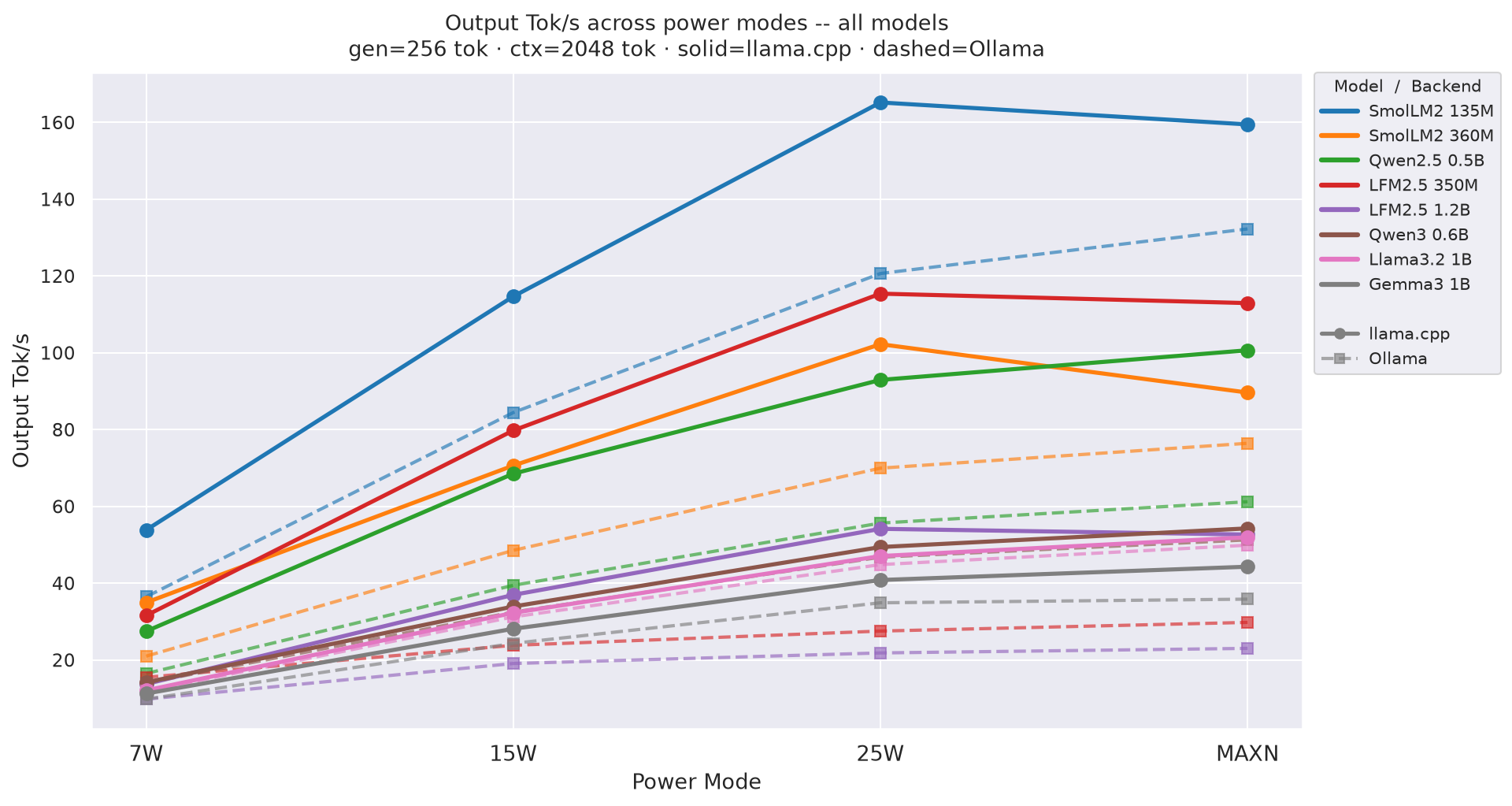
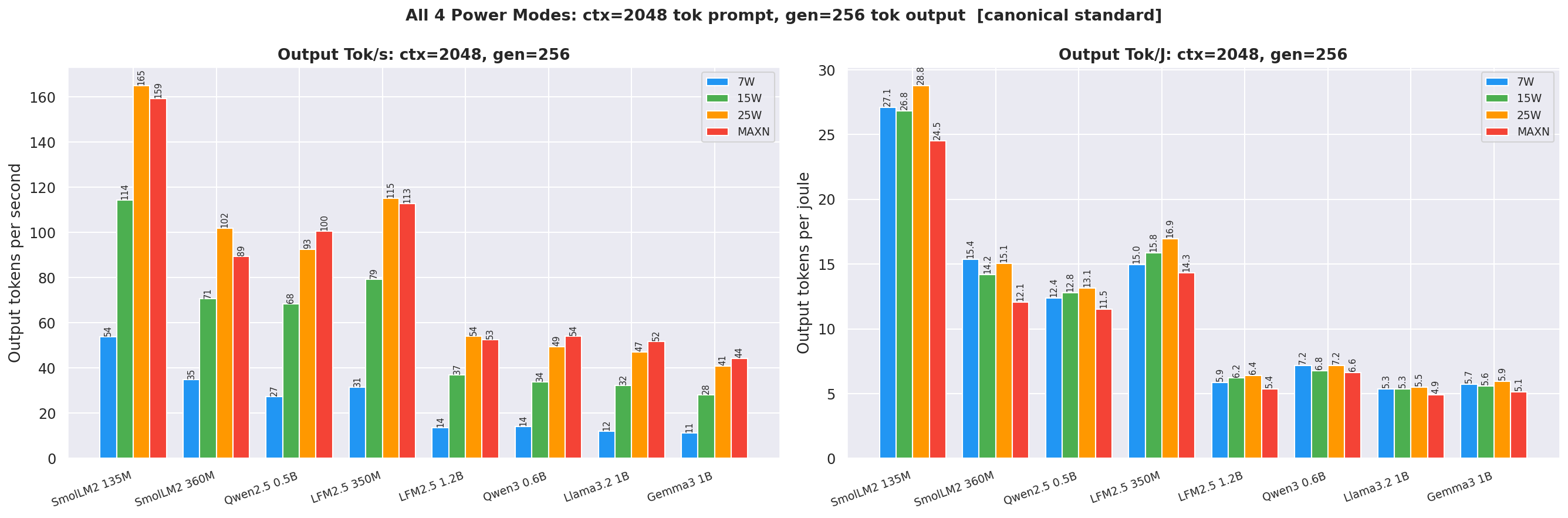
В ходе бенчмарка было установлено, что использование режима питания 25W для бэкенда llama.cpp обеспечивает пропускную способность на 35–47% выше, чем при использовании режима 15W. Среди протестированных моделей лучшую энергоэффективность продемонстрировала SmolLM2-135M, показав результат 29.6 tok/J при скорости генерации 165.2 tok/s.
Контекст
Для эффективного развертывания ИИ на компактных устройствах критически важна низкоуровневая оптимизация. Существует заметный разрыв в производительности между специализированными инструментами, такими как llama.cpp, и более универсальными решениями вроде Ollama, которые на специфических моделях могут работать до 4 раз медленнее.
Почему это важно для индустрии
Результаты подчеркивают необходимость глубокой оптимизации CUDA-ядер под новые архитектуры, например, SSM в LFM2.5. Для индустрии edge-AI это означает переход от простого запуска моделей к стандартизации оптимизированных runtime-сред, где эффективность бэкенда становится определяющим фактором стоимости и возможностей устройства.
Почему это важно для пользователей
Разработчикам локальных ИИ-решений на базе железа NVIDIA рекомендуется использовать режим питания 25W и бэкенд llama.cpp для достижения наилучшего баланса между скоростью работы и энергопотреблением на устройствах Jetson Orin Nano Super.
Источники
Автор
Look at AI, редакция