
Опубликовано видео доклада Ибрагима Бадертдинова из Nebius на конференции AI Engineer Europe, посвященного системе SWE-rebench. Этот динамический бенчмарк позволяет объективно оценивать способности AI-агентов, решая реальные задачи из GitHub и предотвращая утечку данных через ежемесячное обновление наборов задач.


Что произошло
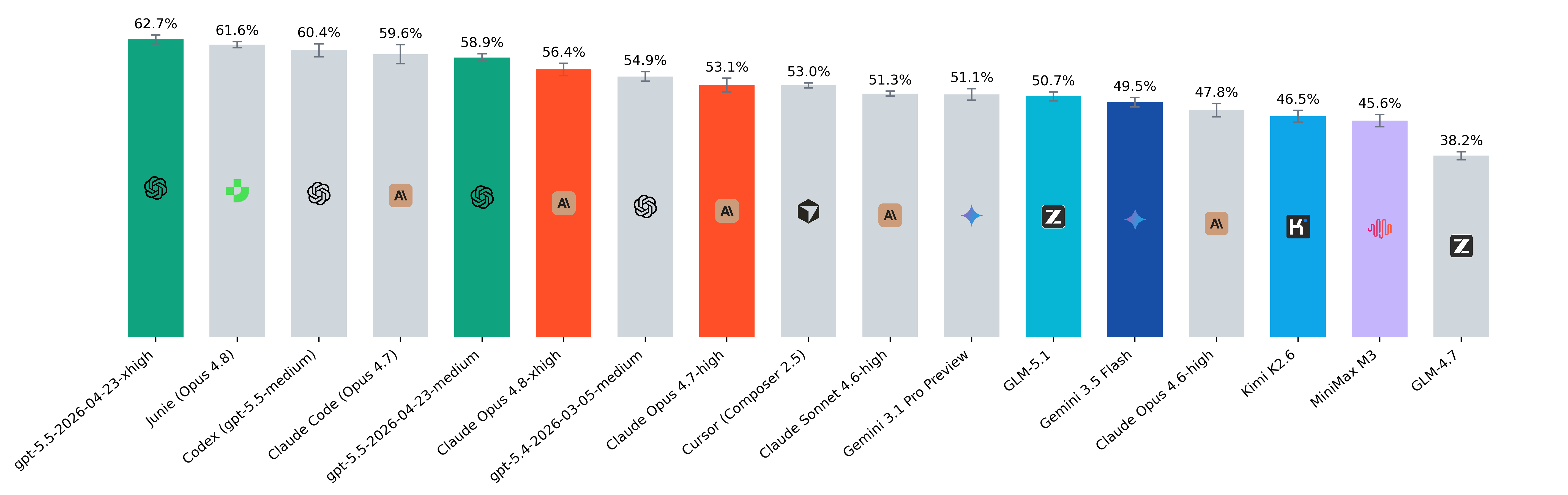
В рамках доклада представлена система SWE-rebench, которая использует подход time-splitting для оценки моделей. В текущем рейтинге лидируют модели gpt-5.5 и Junie с показателем Resolved Rate более 60%, при этом решение задач через Cursor демонстрирует наиболее высокую экономическую эффективность, составляющую $0.23 за задачу.
Контекст
Традиционные статические бенчмарки быстро теряют актуальность из-за контаминации (contamination) — попадания тестовых задач в обучающие выборки моделей. SWE-rebench решает эту проблему, предлагая динамическое обновление задач, что позволяет отличить модели, которые просто 'помнят' готовые решения, от систем, способных реально пользоваться инструментами вроде git, curl и редакторами файлов.
Почему это важно для индустрии
Для индустрии переход к динамическим бенчмаркам означает необходимость развития инфраструктуры для запуска тысяч изолированных сэндбоксов (sandbox). Это становится обязательным условием для создания качественных данных, необходимых для циклов Reinforcement Learning (RL), где агенты обучаются на основе результатов прохождения подобных верифицируемых тестов.
Почему это важно для пользователей
Для разработчиков и пользователей SWE-rebench служит надежным инструментом сравнения AI-кодеров в реальных сценариях, а не на абстрактных тестах. Появление новых метрик, таких как Resolved Rate и cost-efficiency, помогает более осознанно выбирать инструменты разработки, такие как Cursor или специализированные модели.
Что пока неизвестно / ограничения
В то время как техническая и экономическая эффективность оценивается детально, вопросы юридических рисков, связанных с интеллектуальной собственностью и регуляторным статусом таких систем, остаются менее проработанными в рамках данного технического сравнения.
Источники
- SWE-rebench: Lessons from Evaluating Coding Agents — Ibragim Badertdinov, Nebius
- SWE-rebench Leaderboard
Автор
Look at AI, редакция