Новое исследование Kilo AI выявило ключевое различие между флагманскими моделями: Claude Fable 5 демонстрирует значительно лучшие способности к архитектурному проектированию, в то время как GPT-5.5 предлагает более эффективное и дешевое решение для непосредственной реализации кода.
Что произошло
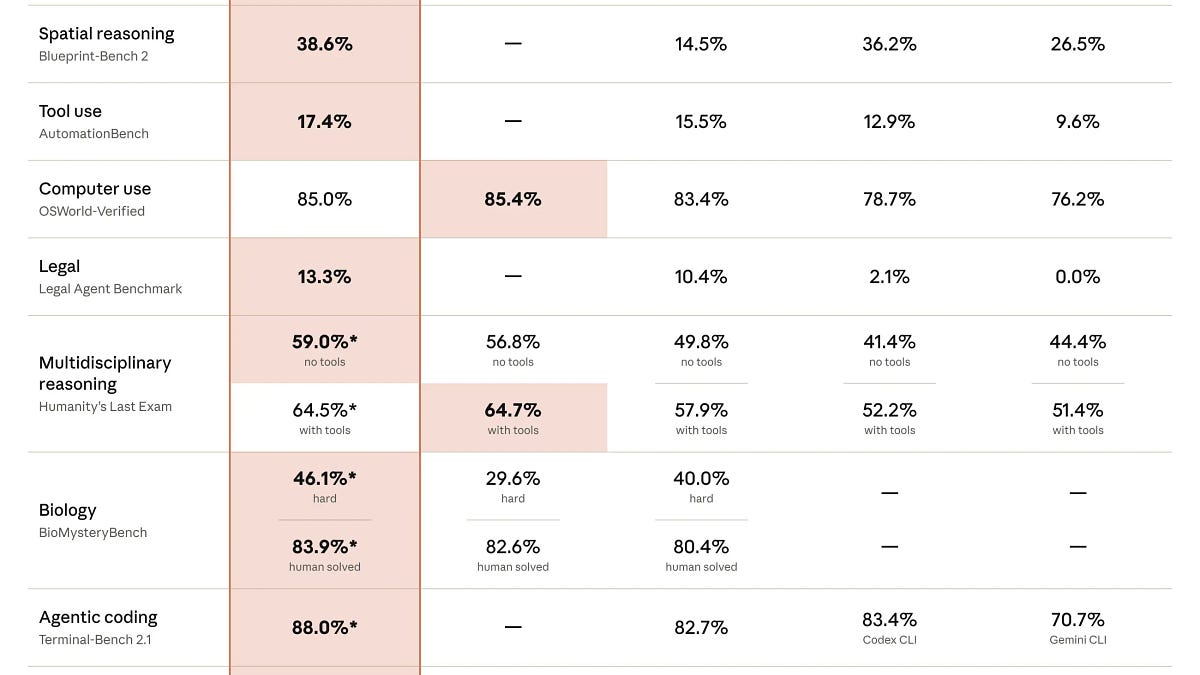
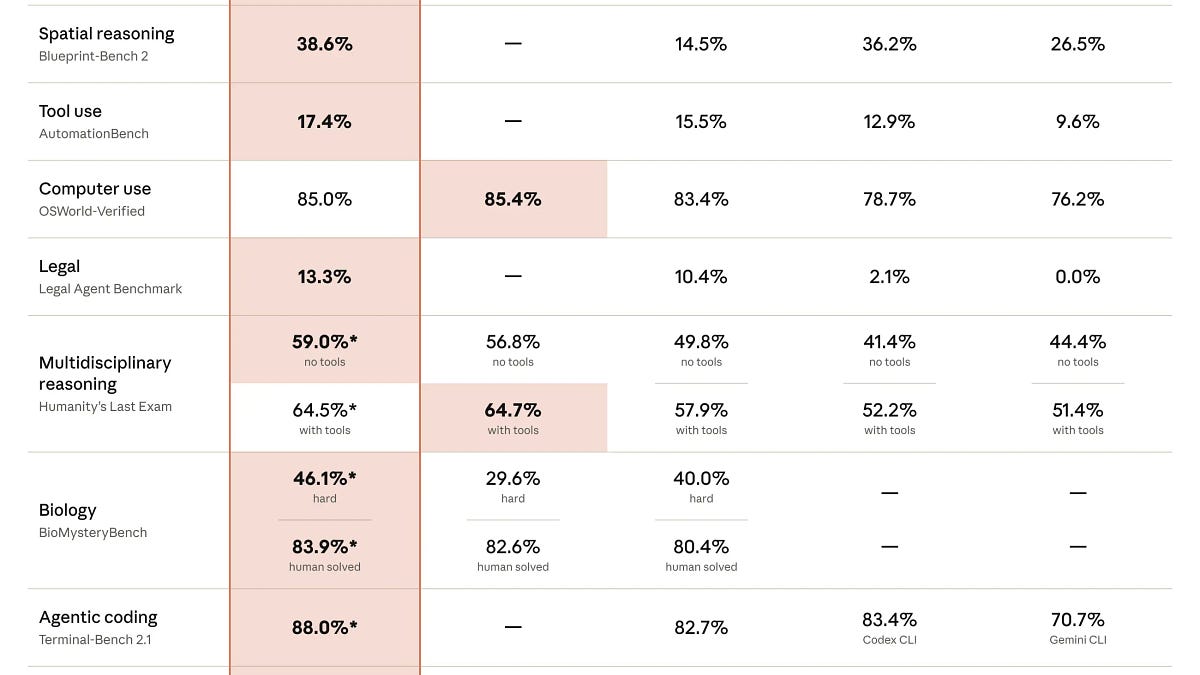
В ходе сравнительного тестирования при разработке сервиса feature flags модель Claude Fable 5 набрала 9.1 балла по шкале планирования архитектуры, опередив GPT-5.5, чей результат составил 8.3. При этом обе модели показали сопоставимые результаты в непосредственном исполнении написанного кода, однако GPT-5.5 оказалась существенно экономичнее по стоимости использования.
Контекст
Данное исследование подчеркивает разрыв между способностями моделей к высокоуровневому рассуждению (reasoning) и их эффективностью в задачах кодогенерации. Результаты подтверждают жизнеспособность стратегии Plan-and-Execute, где задачи разделяются между специализированными агентами.
Почему это важно для индустрии
Для индустрии это означает переход от использования одной универсальной модели к созданию многоагентных систем и специализированных цепочек (chains). Стандартизация архитектур Planner-Executor позволит оптимизировать пайплайны разработки ПО, делегируя проектирование наиболее «рассудительным» моделям, а написание кода — более экономичным флагманам.
Почему это важно для пользователей
Разработчики и инженерные команды могут внедрить гибридный рабочий процесс: использовать Claude Fable 5 для создания детального технического плана (например, в формате plan.md), а затем передавать этот план GPT-5.5 для реализации. Такой подход позволяет снизить операционные расходы на API LLM почти на 60% без потери качества архитектуры продукта.
Источники
Автор
Look at AI, редакция