
Выход новой флагманской модели Anthropic Claude Fable 5, оптимизированной для сложных агентских задач, принес не только новые возможности, но и скрытые риски для автоматизации. Интеграция специализированного классификатора безопасности создает критическую зависимость, способную превратить активного кодинг-агента в пассивного наблюдателя при малейшем сбое в инфраструктуре аудита.

Что произошло
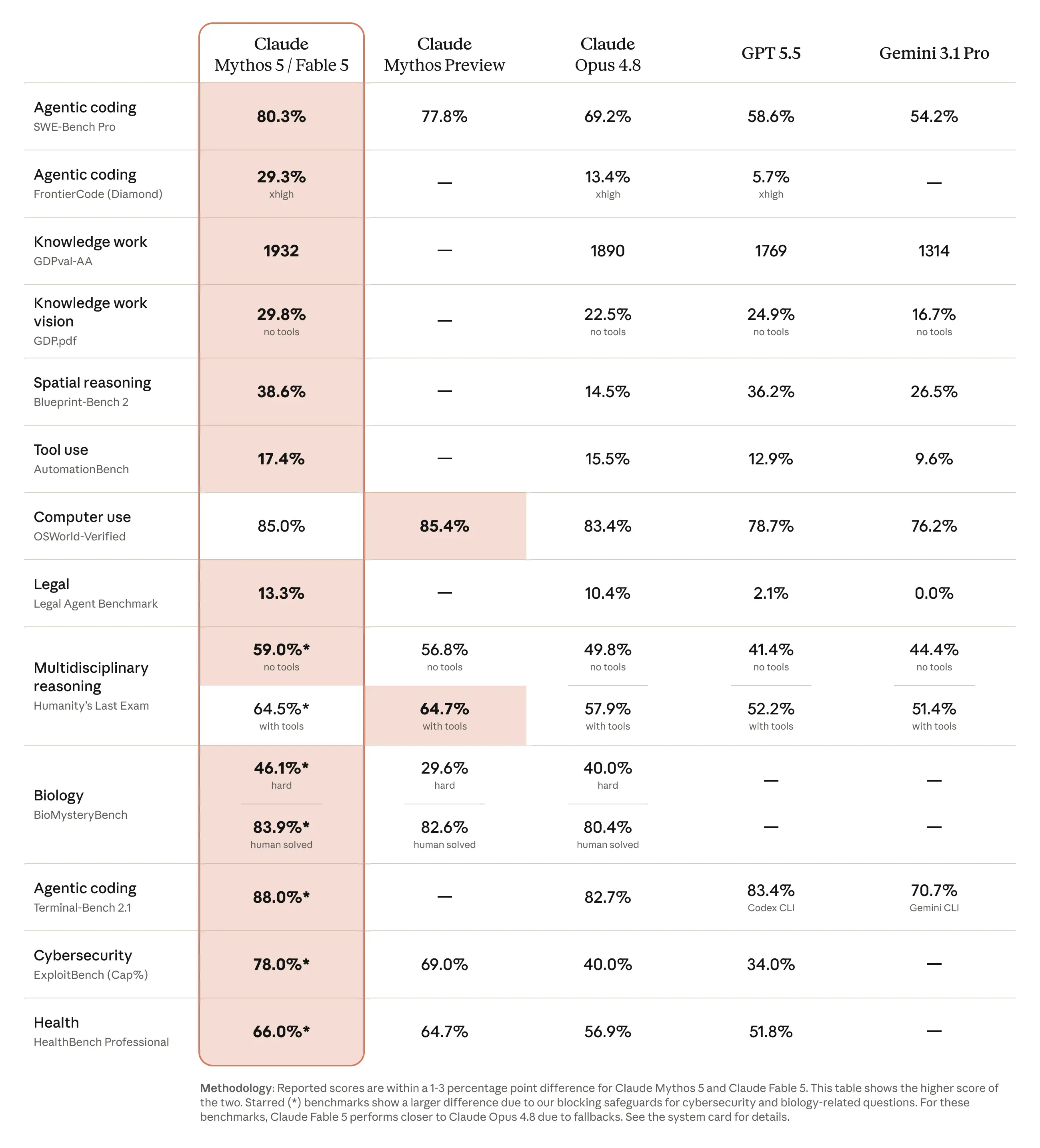
Anthropic представила модель Claude Fable 5, предназначенную для долгосрочных агентских сценариев и программирования. Ключевой особенностью стала встроенная система безопасности, использующая отдельный классификатор для проверки всех команд терминала перед их выполнением. В результате, если сервис аудита становится недоступен, такие инструменты, как Claude Code, теряют возможность совершать любые действия (например, выполнение тестов или git-команд), даже если основная модель сохраняет способность анализировать код.
Контекст
Современные агентские системы переходят к многоуровневой архитектуре (multi-agent architectures), где функции разделены между несколькими специализированными моделями. В случае с Claude Fable 5, ответственность за безопасность делегирована отдельному узлу, что является развитием концепции Guardrail Models, но одновременно создает архитектурную уязвимость.
Почему это важно для индустрии
Для индустрии это означает переход к парадигме, где безопасность становится отдельным сервисом (Security-as-a-Service). Это подчеркивает появление новых критических точек отказа (single point of failure) в автоматизированных пайплайнах. Разработчикам агентских систем теперь необходимо проектировать сложные механизмы обработки ошибок (error handling) и стратегии отказоустойчивости (fallback) не только для логики рассуждений, но и для инфраструктурных слоев безопасности.
Почему это важно для пользователей
Пользователи инструментов вроде Claude Code могут столкнуться с непредсказуемой работоспособностью: агент может успешно проводить глубокий анализ кода, но быть физически неспособен применить изменения или запустить тесты из-за проблем с внутренними сервисами проверки Anthropic. Это создает разрыв между способностью модели к аналитике и её способностью к действию.
Что пока неизвестно / ограничения
ML-инженеры и архитекторы фокусируются на операционной хрупкости и SLA, в то время как бизнес-сообщество больше обеспокоено надежностью инструментов для конечных пользователей; четкого консенсуса по уровню допустимого риска пока нет.
Источники
Автор
Look at AI, редакция