Команда OpenMOSS представила MOSS-Video-Preview — новую мультимодальную базовую модель, способную анализировать видеопоток в режиме реального времени с крайне низкой задержкой.


Что произошло
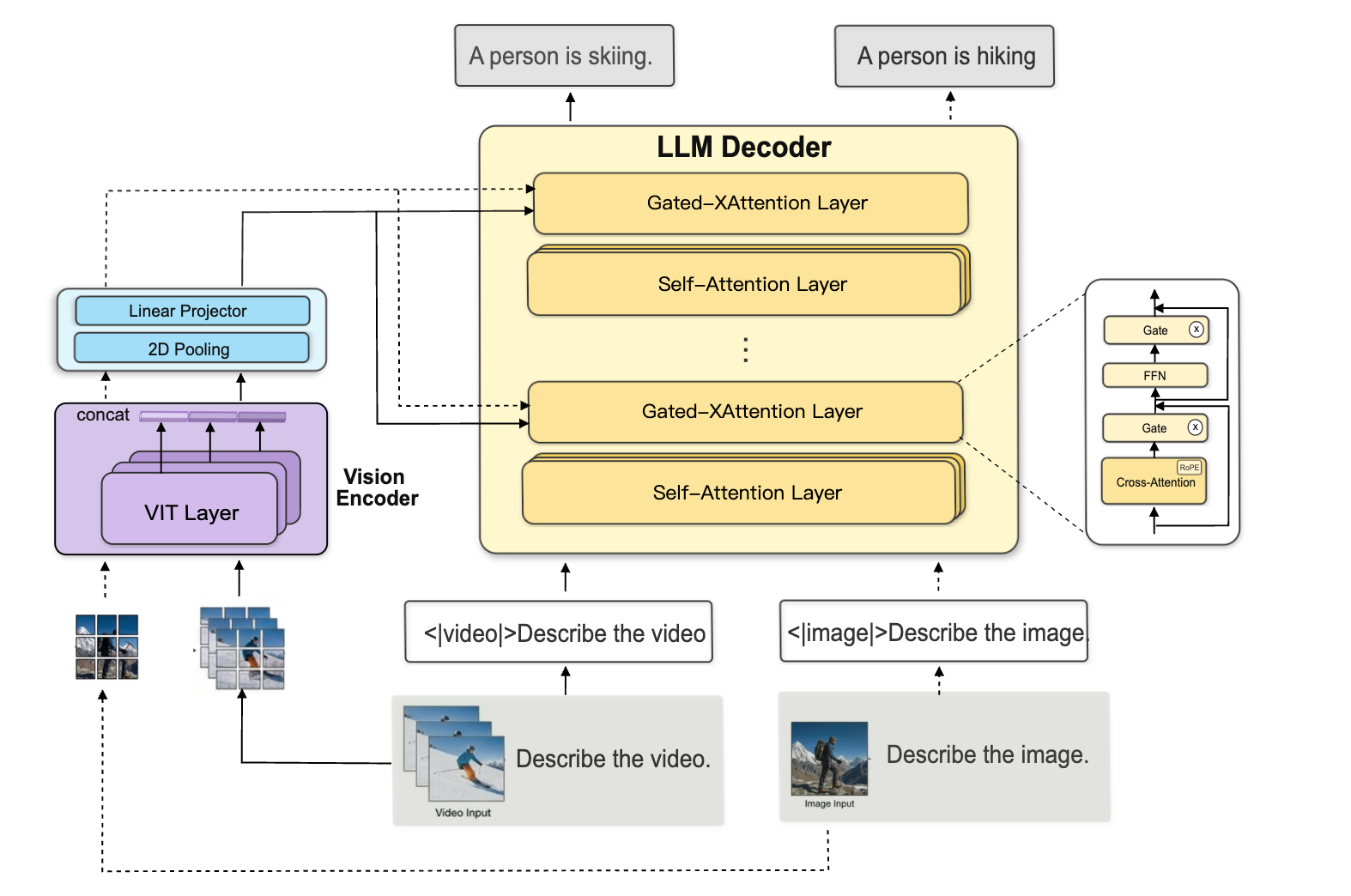
Разработанная на базе архитектуры Llama-3.2-Vision, модель MOSS-Video-Preview объемом около 11 млрд параметров поддерживает потоковую обработку (streaming inference). Ключевой технической особенностью является использование механизма gated cross-attention, который позволяет эффективно разделять визуальные и лингвистические признаки при обработке данных.
Контекст
В отличие от традиционных методов, полагающихся на пакетную обработку видеофрагментов, данное решение нацелено на нативное понимание потока. Это позволяет модели реагировать на изменения в визуальном контексте практически мгновенно, избегая задержек, связанных с необходимостью буферизации целых видеофайлов или крупных сегментов.
Почему это важно для индустрии
Для индустрии ИИ переход от пакетного анализа к нативному realtime-пониманию через архитектуру cross-attention открывает путь к созданию по-настоящему интерактивных AI-ассистентов. Использование открытых весов и кода предоставляет мощный инструмент для быстрого прототипирования Video Language Models (VLM) нового поколения.
Почему это важно для пользователей
Для конечных пользователей это означает появление технологий, способных «видеть» и вести диалог о происходящем в прямом эфире — например, в видеозвонках или стримах — обеспечивая полноценное взаимодействие с визуальным контекстом почти без задержек.
Что пока неизвестно / ограничения
Существуют вопросы, касающиеся безопасности потоковых данных и управления задержками (latency management), которые критически важны для внедрения технологии в промышленную эксплуатацию (production).
Источники
- GitHub - OpenMOSS/MOSS-Video-Preview
- MOSS-Video-Preview Collection on Hugging Face
- MOSS-Video-Preview: Toward Real-Time Video Understanding via Cross-Attention (arXiv)
Автор
Look at AI, редакция