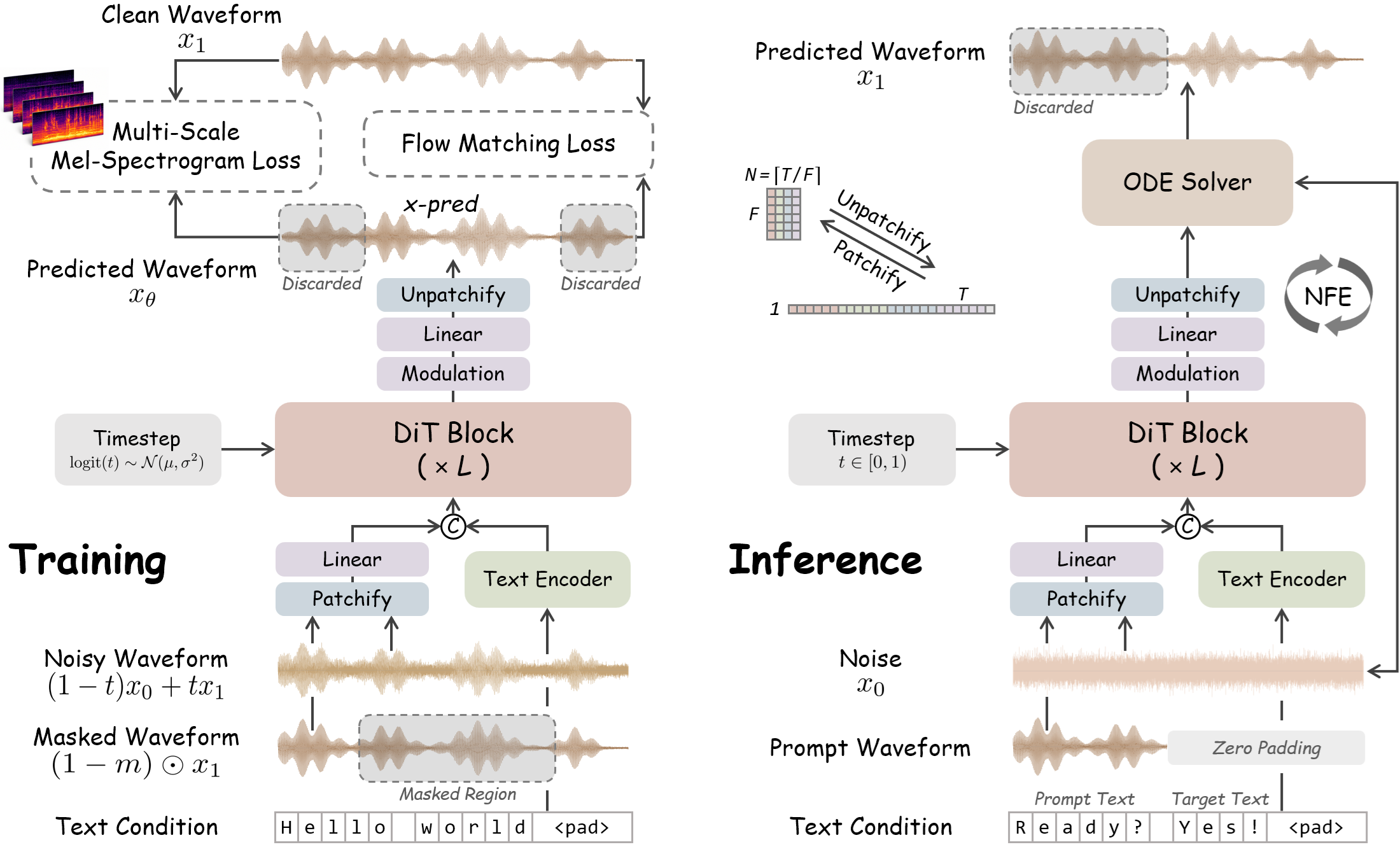
🎙 WavTTS: Direct Audio Waveform Synthesis
WavTTS has been introduced—the first zero-shot TTS framework that models raw audio waveforms directly, bypassing intermediate stages such as mel-spectrograms. The model is built on a Flow Matching and Diffusion Transformer architecture.
🌍 Moving to direct waveform modeling eliminates information loss and allows for the creation of more accurate end-to-end speech synthesis systems.
👤 This is a step toward more natural voice cloning. The project has open-source code (MIT), but the weights are under CC BY-NC 4.0.
Source 1: https://wavtts.github.io/ Source 2: https://github.com/cwx-worst-one/WavTTS