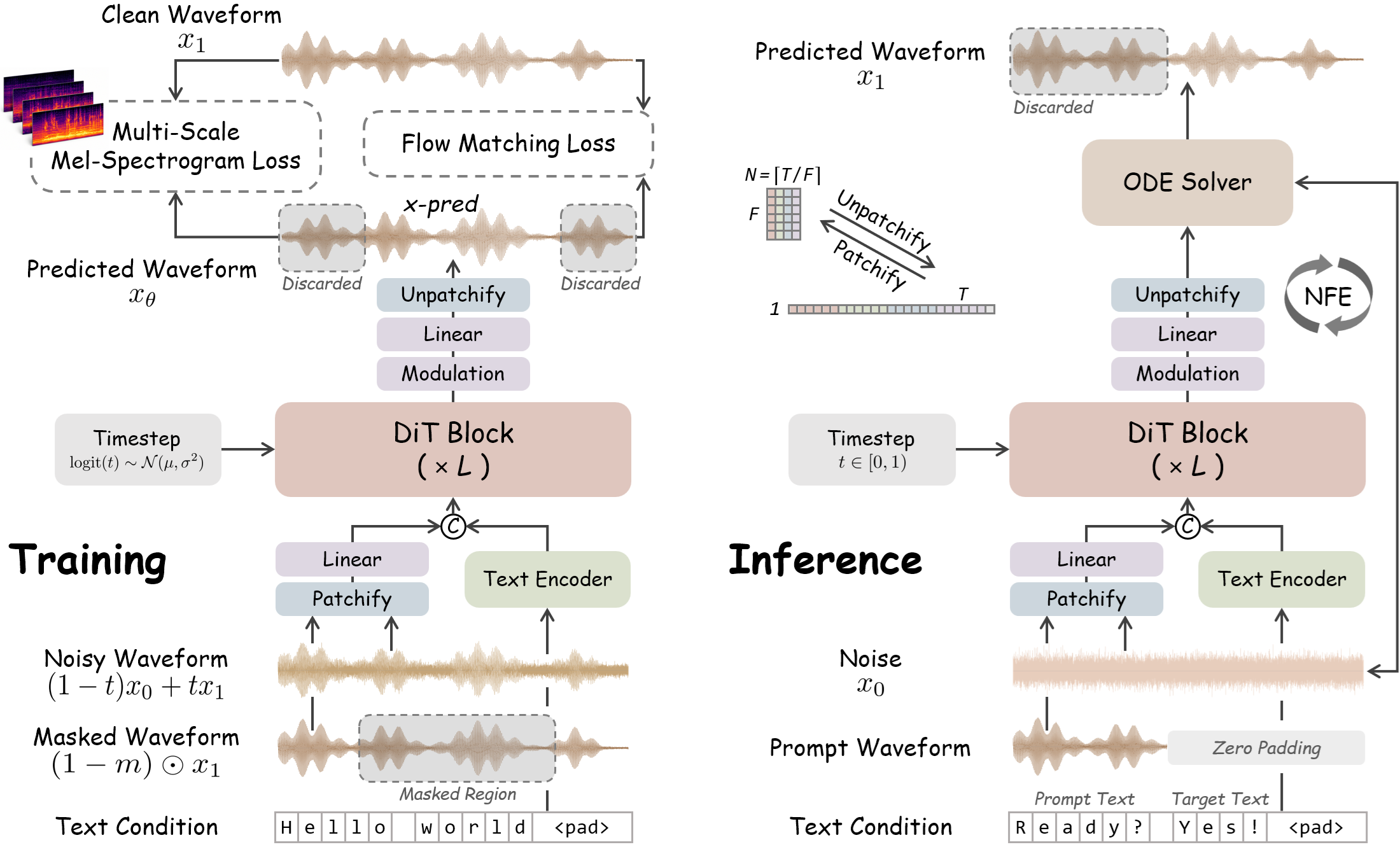
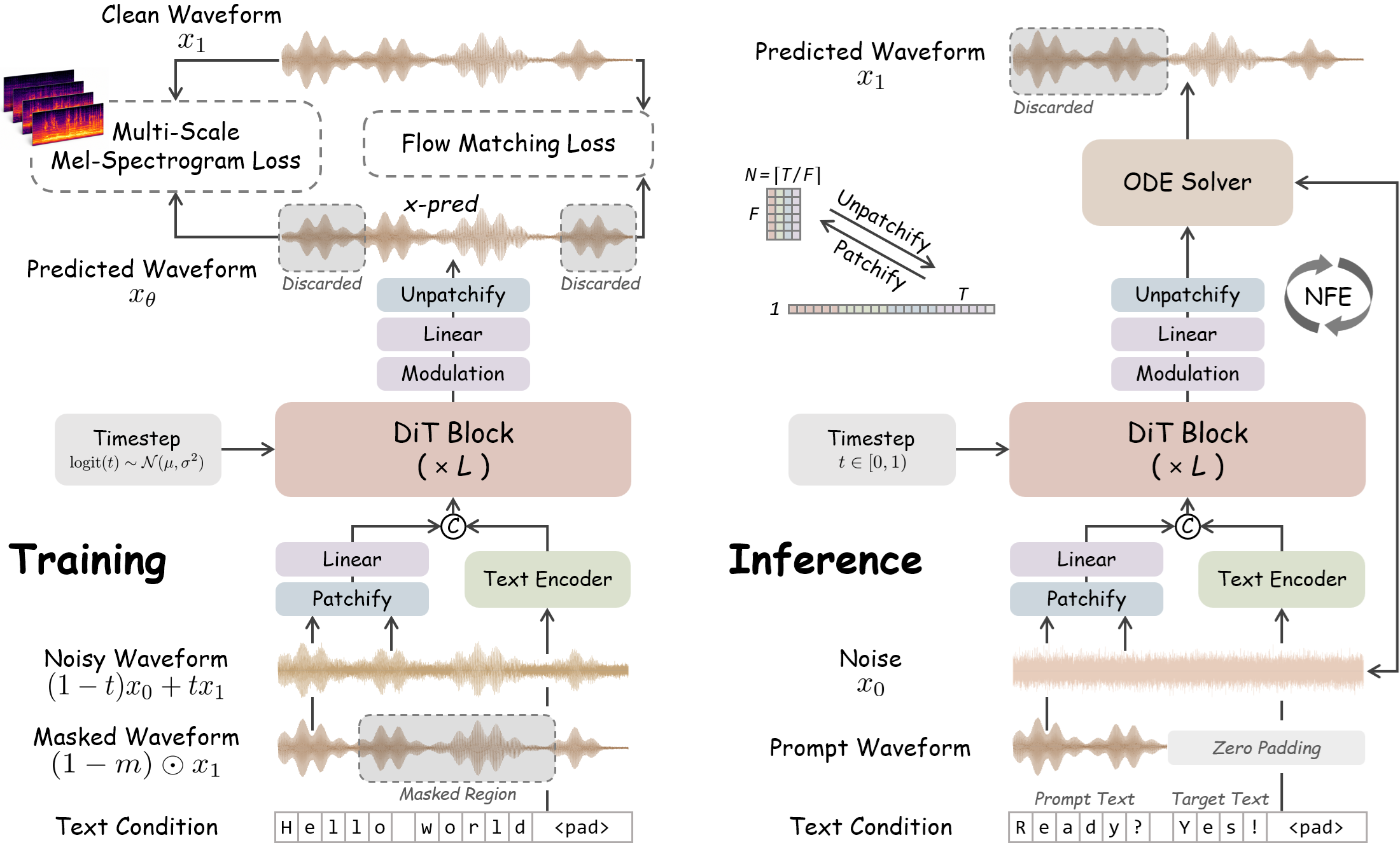
WavTTS has been introduced—the first framework for zero-shot speech generation that models raw audio waveforms directly, bypassing intermediate stages such as mel-spectrograms. The model utilizes a Flow Matching architecture with a Diffusion Transformer (DiT) and a patchification strategy for efficient handling of long audio sequences.

What Happened
Developers have introduced WavTTS, a speech synthesis system built on Flow Matching and Diffusion Transformer. Unlike traditional methods, WavTTS provides high-quality synthesis at a 16 kHz sampling rate by working directly with raw waveforms. The project is open-source (MIT license) with weights available on Hugging Face.
Context
Most modern speech synthesis systems use intermediate representations, such as mel-spectrograms or VAE latent spaces. While this simplifies the task, such an approach inevitably leads to information loss during signal compression. WavTTS proposes a shift toward end-to-end architectures that model the audio signal in its entirety.
Why It Matters for the Industry
Moving to direct waveform modeling allows for the elimination of information loss characteristic of spectrogram-based methods and creates a foundation for more accurate end-to-end systems. In the long term, this could lead to a paradigm shift in TTS research: from hybrid pipelines to pure diffusion models for direct signal modeling.
Why It Matters for Users
For users and developers, this means the possibility of creating more natural and high-quality voice cloning in local workflows. Thanks to the open-source code and weights, WavTTS can be integrated into tools like ComfyUI for running high-quality synthesis locally without relying on cloud APIs.
What Is Not Yet Known / Limitations
Despite the code being open under the MIT license, the model weights are distributed under the CC BY-NC 4.0 license, which imposes restrictions on commercial use.
Sources
Author
Look at AI, Editorial Team