🚀 **LLM Reinforcement Learning via Pure CUDA**
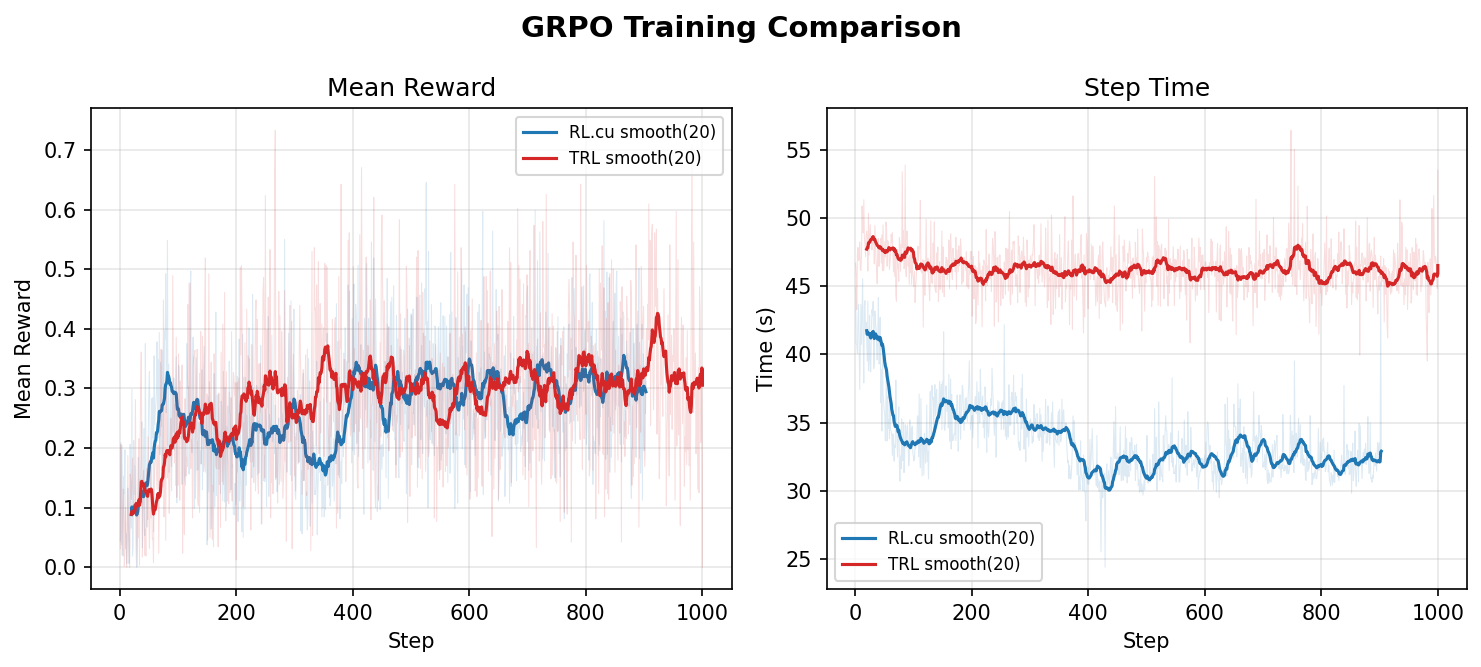
The RL.cu project has been presented, enabling a full reinforcement learning cycle (SFT + GRPO) on pure CUDA/C++ without dependency on PyTorch. The system includes hand-written kernels (FlashAttention-2, RMSNorm, RoPE, AdamW) and an engine featuring continuous batching and Paged KV cache. Tests on Qwen3-0.6B showed a 1.37x speedup compared to the TRL + vLLM stack.
🌍 The project eliminates the gap between training and inference phases (train-inference mismatch), allowing for the use of unified weights and processes, which radically reduces overhead and dependency on heavy libraries.
👤 Developers gain a tool for maximizing GPU efficiency by minimizing memory management and data transfer latencies.
Source 1: https://github.com/KJLdefeated/RL.cu