A developer has introduced the RL.cu project—a system for training large language models (LLMs) using reinforcement learning (RL) exclusively with CUDA and C++. The project allows for the implementation of a full training cycle without dependency on the heavyweight PyTorch framework, significantly increasing GPU utilization efficiency.


What Happened
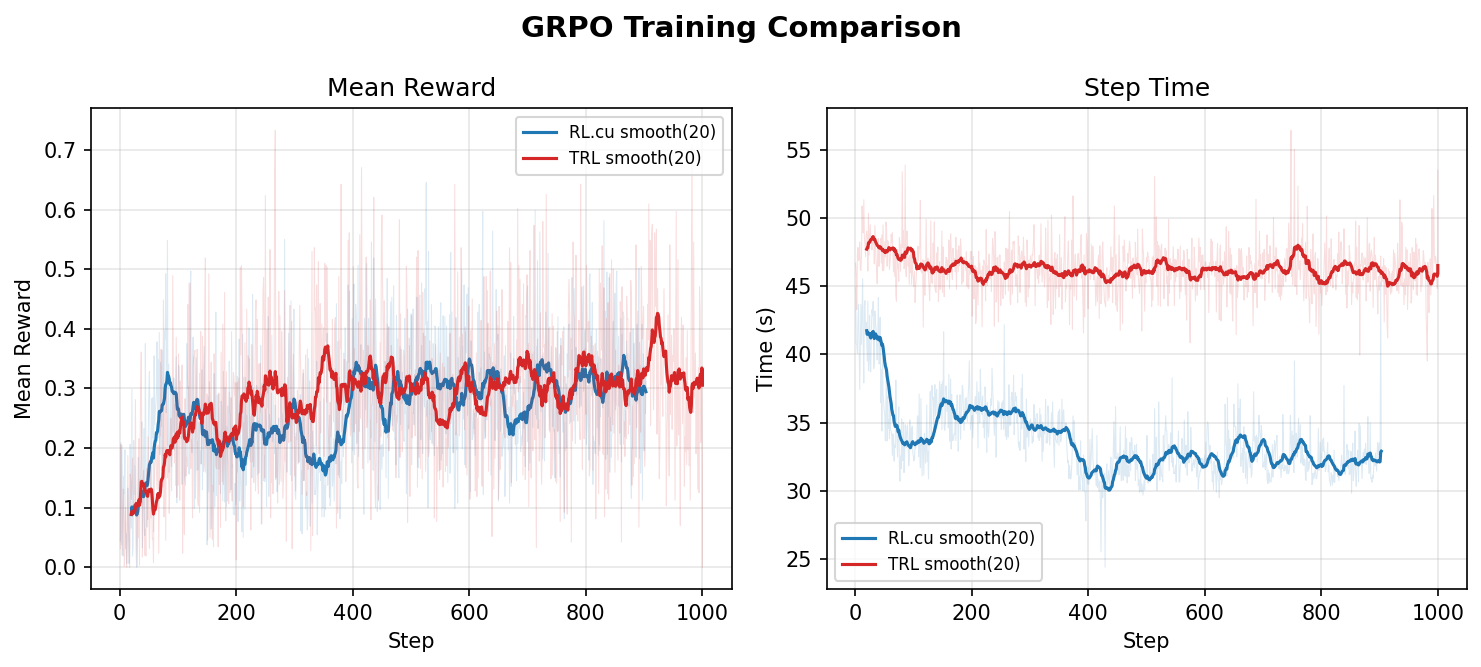
The open-source project RL.cu has been presented, implementing the full Reinforcement Learning cycle (SFT + GRPO) on pure CUDA/C++. The system includes hand-written kernels (FlashAttention-2, RMSNorm, RoPE, AdamW) and a specialized inference engine with support for continuous batching and Paged KV cache. According to benchmarks on the Qwen3-0.6B model, the solution provides a 1.37x speedup in training time (wall-clock) compared to the standard TRL + vLLM stack while maintaining a comparable reward level.
Context
Modern LLM RL training processes typically rely on high-level libraries like PyTorch, which creates a train-inference mismatch between the training and inference phases. Using a unified process and shared weights in RL.cu allows for eliminating this gap and reducing overhead related to memory management and data transfer.
Why It Matters for the Industry
The project demonstrates the possibility of moving toward vertically integrated, 'bare-metal' training stacks. This paves the way for creating ultra-efficient and lightweight systems that can radically reduce operational costs for model training and eliminate dependency on universal but heavyweight frameworks.
Why It Matters for Users
Developers and researchers gain a tool for conducting highly performant and inexpensive RL experiments (SFT + GRPO) on existing hardware, minimizing latency and simplifying the dependency stack when working with small and medium-sized models.
What Is Not Yet Known / Limitations
There are risks associated with the complexity of maintenance and ensuring reliability when moving away from proven industry standards like PyTorch.
Sources
Author
Look at AI, Editorial Team