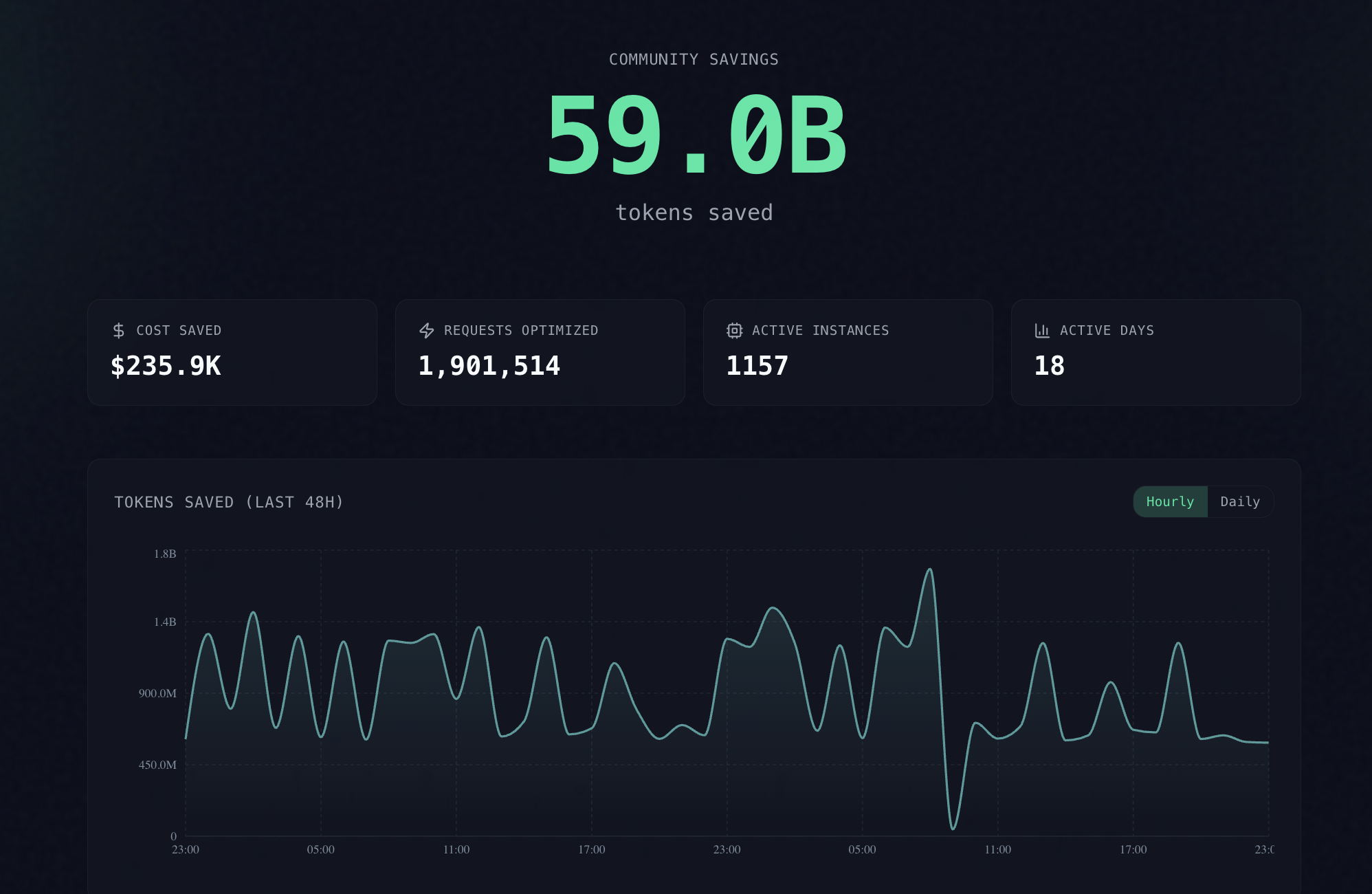
📉 Headroom: Save up to 95% on tokens when working with AI agents
Headroom, a tool for compressing context (logs, files, RAG chunks) before sending it to an LLM, has been released. The technology allows for a 60–95% reduction in token consumption without losing response accuracy.
🌍 Reduces inference costs and latency in agentic architectures.
👤 Allows for saving API budget and receiving faster responses from AI agents.
Source 1: https://github.com/chopratejas/headroom