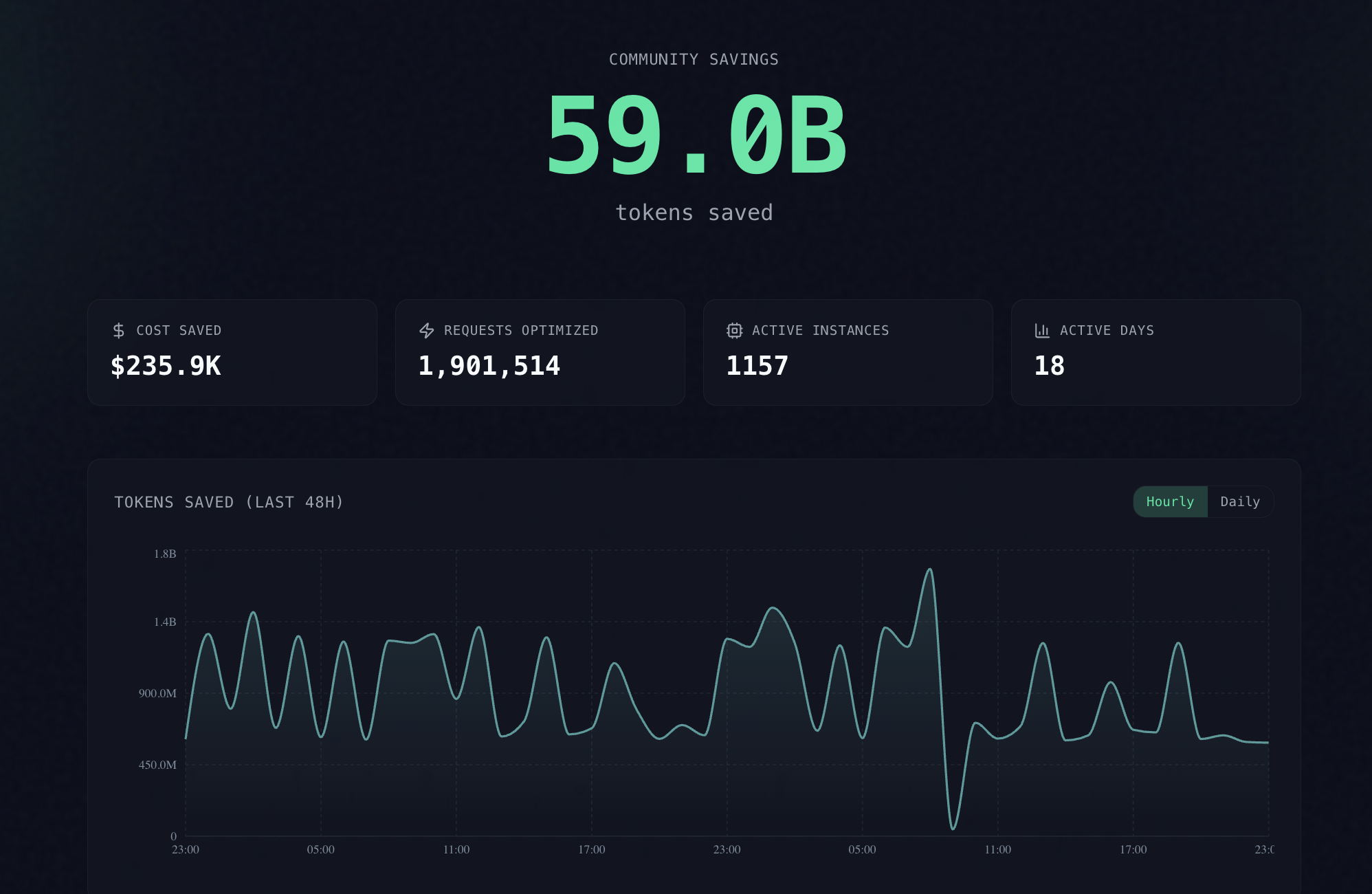
Headroom has been released—a new tool designed to optimize the context of AI agents by compressing logs, files, RAG chunks, and tool outputs before they are sent to an LLM. The technology allows for a reduction in token consumption by 60–95% without significant loss in response accuracy.

What Happened
Developers have introduced Headroom, a tool for local compression of data transmitted to large language models. The system utilizes specialized algorithms: AST (Abstract Syntax Tree) for code, structural compression for JSON, and the Kompress-v2-base model for plain text. One of the key features is support for Contextual Compression Reversal (CCR), which allows original data to be reconstructed upon request.
Context
In modern agentic architectures, working with long contexts requires massive computational resources and API costs. Traditional context management methods often rely on simple text truncation, which leads to the loss of important data. Headroom offers a transition toward intelligent information density management.
Why It Matters for the Industry
For the industry, this means a significant reduction in inference costs and decreased latency when working with long contexts. The technology directly optimizes the use of provider KV-caches, increasing the overall efficiency of AI agent infrastructure.
Why It Matters for Users
Users and developers will be able to significantly save on API budgets (such as OpenAI or Anthropic) and receive faster responses from AI agents. The tool allows for the use of longer contexts within existing limits without sacrificing system performance quality.
What Is Not Yet Known / Limitations
There are potential compliance and privacy risks when using third-party compression algorithms, which requires attention from data protection specialists.
Sources
Author
Look at AI, Editorial Team