
Apple has released the third generation of its base model family, AFM 3, which brings a revolutionary approach to neural network operation on mobile devices through optimized memory usage.


What Happened
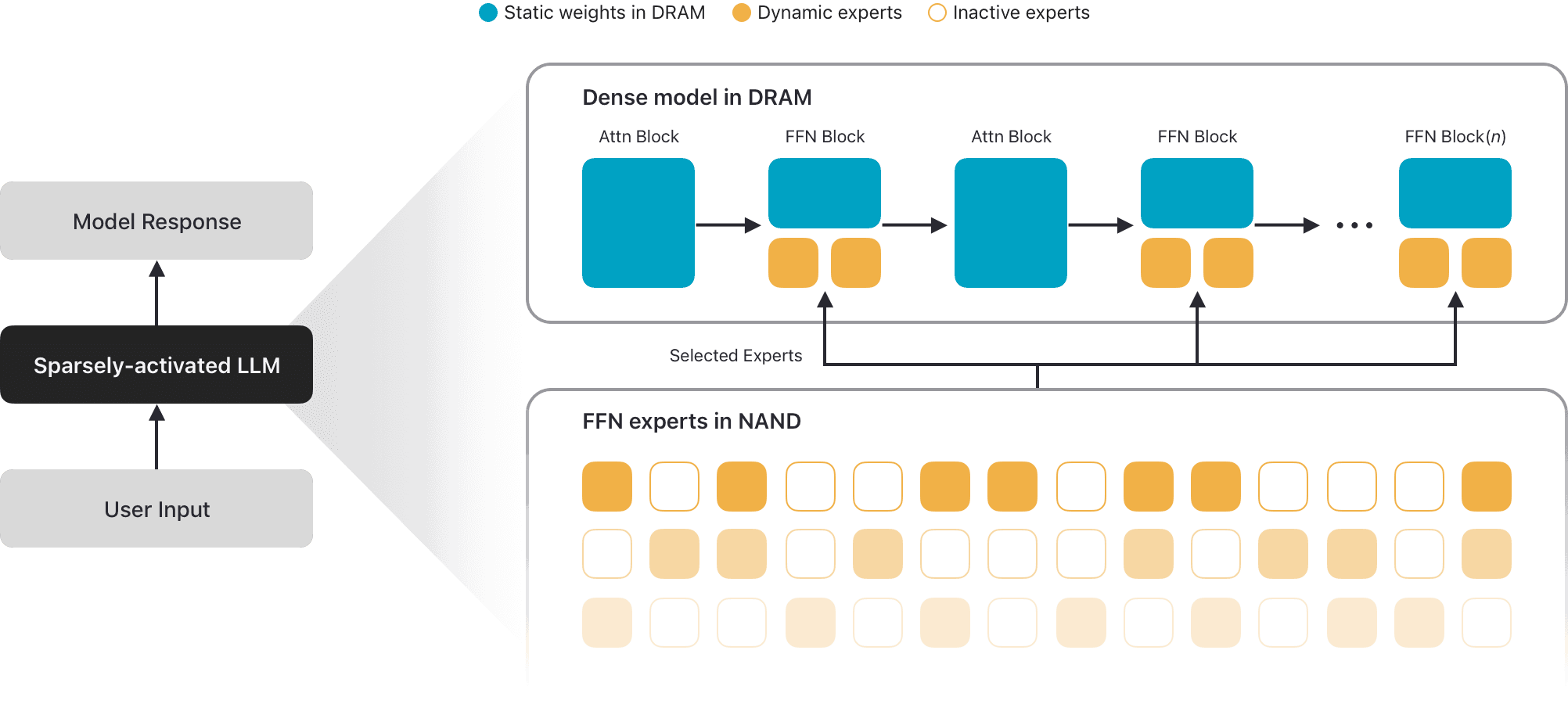
Apple introduced the AFM 3 multimodal models, including AFM 3 Core Advanced. The innovative architecture allows for 20B parameters to be stored in flash memory, activating only 1–4B parameters during query execution. This provides the performance of a 3B model with the quality of a 20B model. For resource-intensive tasks, AFM 3 Cloud Pro is provided, running on NVIDIA via Google Cloud through the Private Cloud Compute system.
Context
Unlike traditional Mixture-of-Experts (MoE) approaches, where expert selection occurs at the token level, AFM 3 uses prompt-level routing. This minimizes data movement between NAND and DRAM, which is critical for devices with limited RAM capacity.
Why It Matters for the Industry
Apple is setting a new standard for MoE optimization for Edge devices, demonstrating the viability of the NAND-to-DRAM method for running heavy models on limited hardware. This could spark research interest in architectures that minimize RAM load through efficient use of flash memory.
Why It Matters for Users
Users of future iPhones and Macs will have access to powerful AI agents capable of instantly processing text, voice, and images locally. This will ensure high speed and data privacy without the need for constant cloud access, even if the model size significantly exceeds the device's available RAM.
Sources
Author
Look at AI, Editorial Team