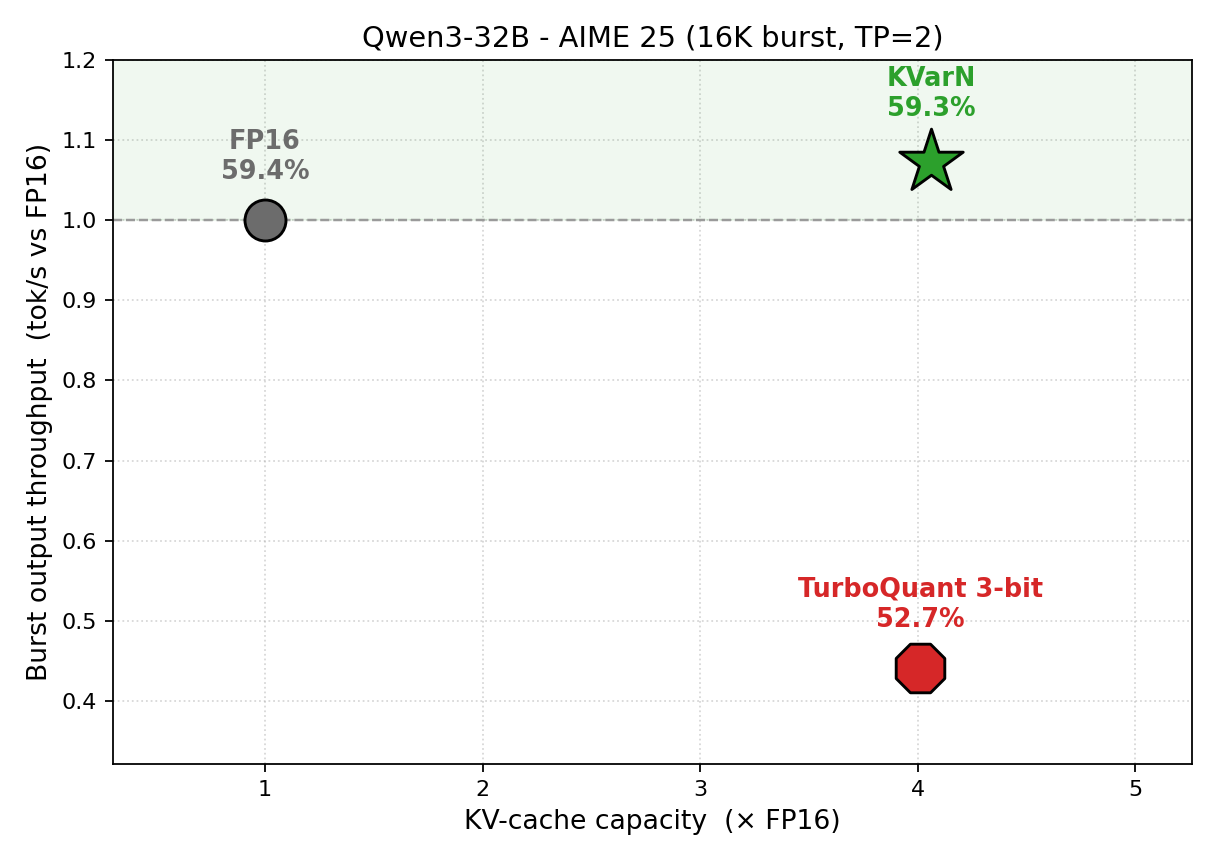
💻 Huawei представила KVarN — бэкенд для квантования KV-кэша, интегрированный в vLLM.
Метод использует вариационную нормализацию через Hadamard-ротацию каналов и итеративную нормализацию дисперсии. Это позволяет увеличить емкость KV-кэша в 3–5 раз при сохранении точности на уровне FP16.
🌍 Решает проблему деградации точности при агрессивном квантовании, что критически важно для моделей с длинным контекстом.
👤 Позволяет запускать мощные LLM с огромным контекстом на значительно меньшем объеме GPU-памяти без потери качества.
Источник 1: https://github.com/huawei-csl/KVarN Источник 2: https://arxiv.org/abs/2606.03458