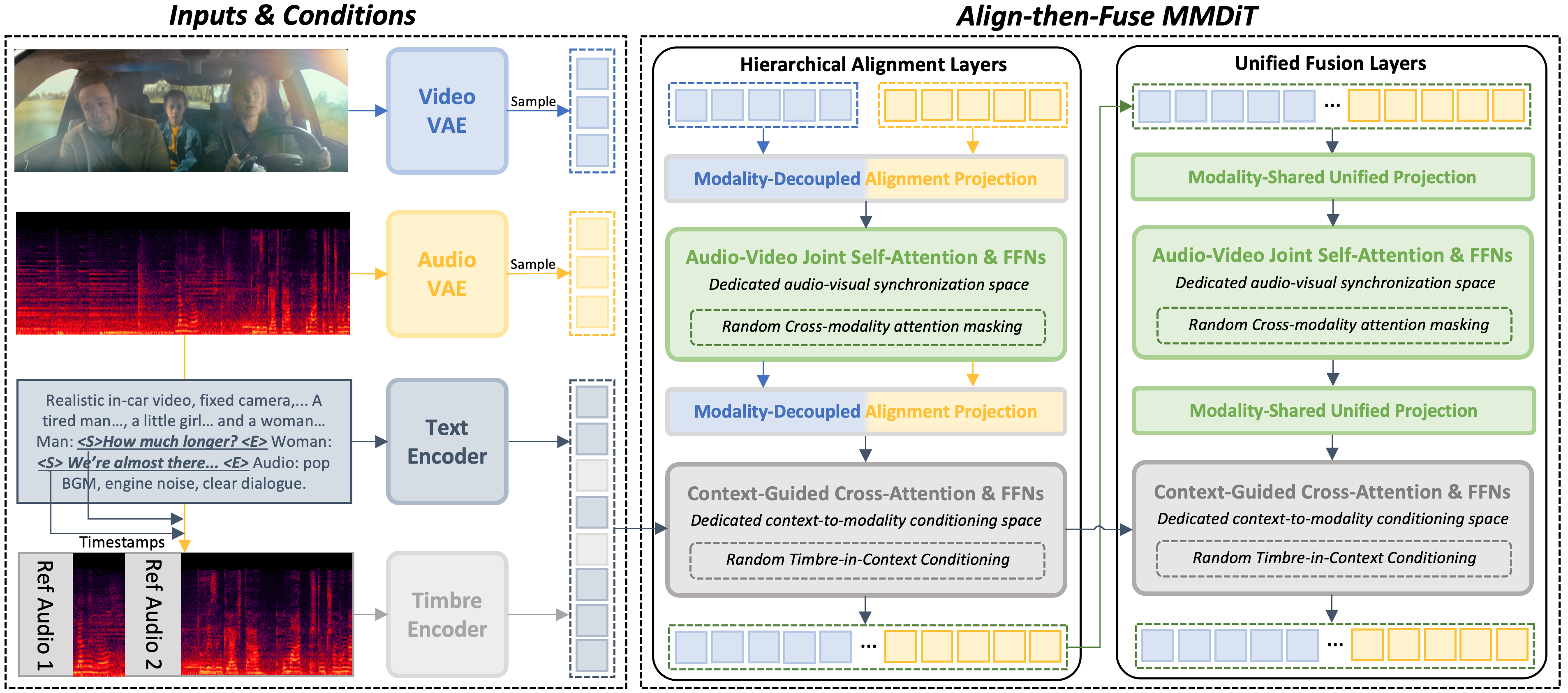
🎨 Baidu представила NAVA — открытую модель для генерации синхронизированного аудио и видео.
Модель с 6,3 млрд параметров использует архитектуру Align-then-Fuse MMDiT для высокой точности синхронизации. NAVA поддерживает генерацию видео в разрешении 720p примерно за одну минуту на 8 GPU и позволяет управлять голосом через референсные WAV-файлы.
🌍 NAVA доказывает, что эффективная мультимодальная генерация возможна при меньшем количестве параметров (в 2-5 раз меньше конкурентов) благодаря специализированному пространству выравнивания. Это снижает порог входа для создания качественного AV-контента.
👤 Теперь можно создавать видео с качественным звуком и уникальным тембром голоса по одному текстовому промпту, предоставив лишь образец аудио.
Источник 1: https://ernie-research.github.io/NAVA/ Источник 2: https://github.com/ernie-research/NAVA