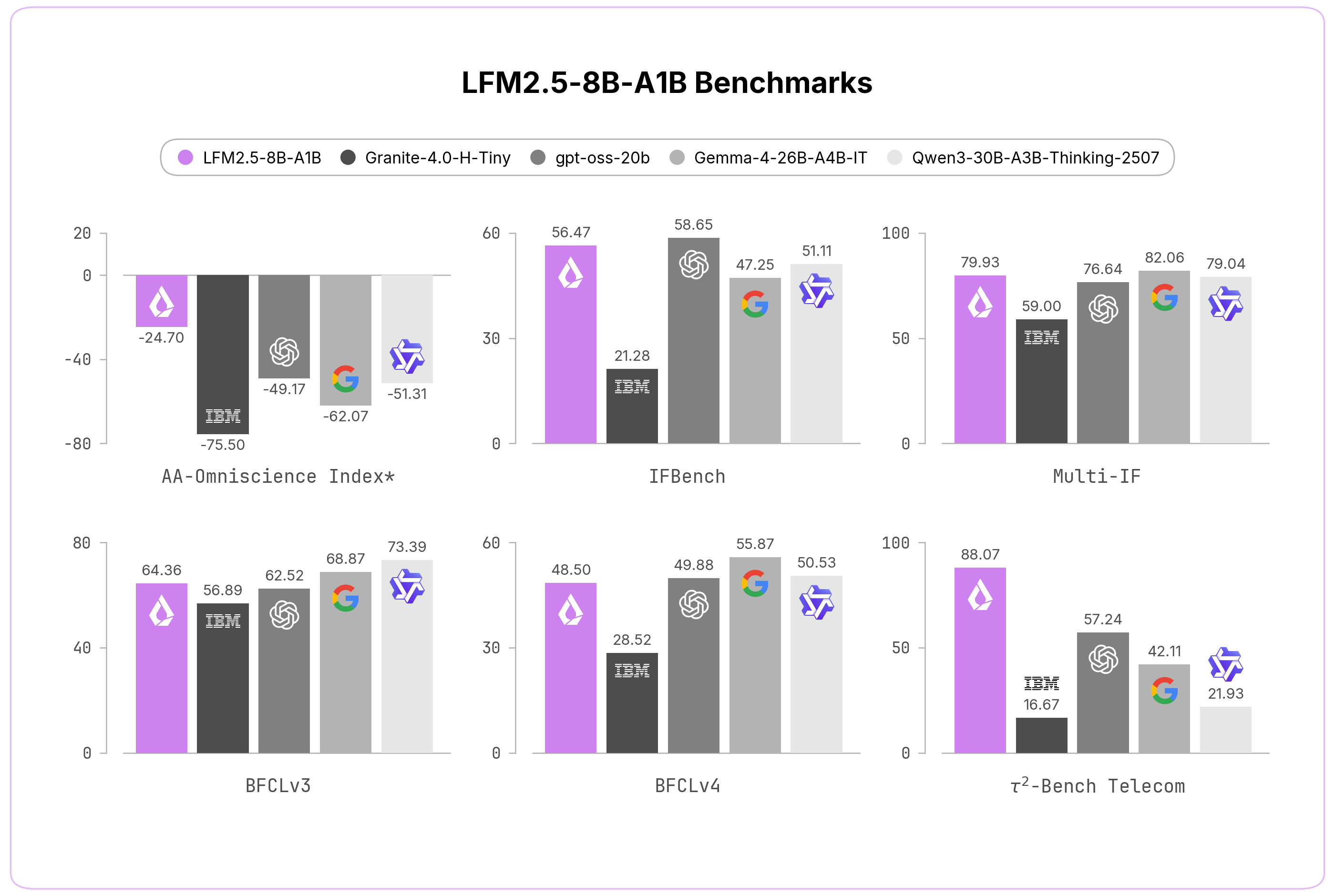
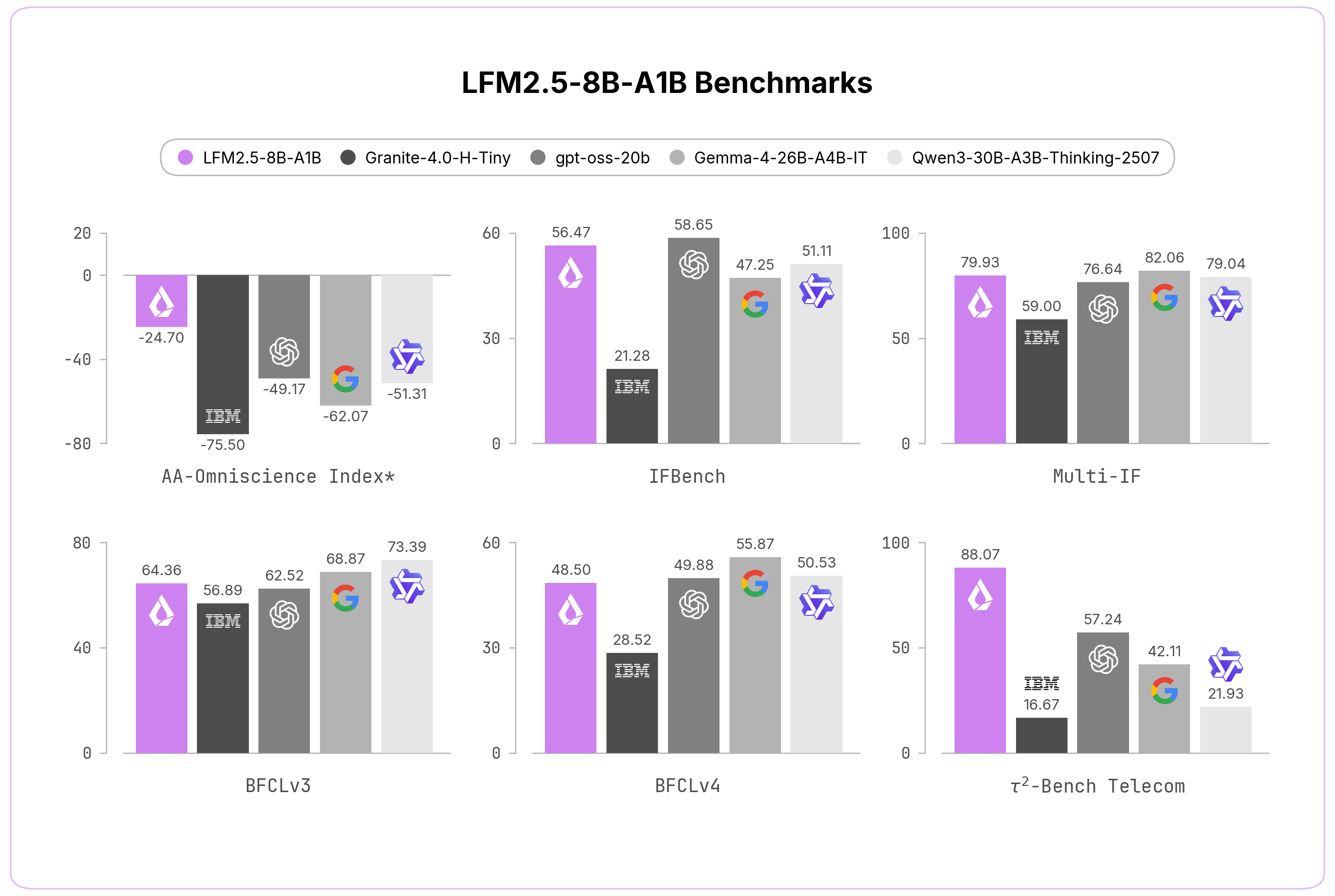
Рынок больших языковых моделей активно сегментируется в зависимости от доступного объема видеопамяти, предлагая решения от компактных моделей для edge-устройств до гигантских систем для исследовательских кластеров.


Что произошло
Представлен обзор актуальных LLM, оптимизированных под конкретные объемы VRAM. В сегменте 8–12 ГБ выделена LiquidAI LFM2.5-8B-A1B (MoE с 1.5B активными параметрами). Для 16–32 ГБ рекомендована мультимодальная Gemma 4 12B от Google. В диапазоне 32–96 ГБ представлены агентские модели Nex-N2-Mini и Qwopus 3.6-27B. Для систем с 384–768 ГБ предлагаются Nex-N2-Pro и Macaron V1 Preview-749B на базе GLM-5.1.
Контекст
Разнообразие архитектур, таких как Mixture of Experts (MoE) и Mixture of Layers (MoL), позволяет эффективно распределять вычислительные задачи. Это создает возможность для создания специализированных edge-агентов и каскадных систем инференса, где сложность модели динамически масштабируется под доступное железо.
Почему это важно для индустрии
Расширение доступности высокопроизводительных моделей через оптимизированные архитектуры позволяет запускать мощные AI-агентов на потребительском и полупрофессиональном железе, снижая зависимость от облачной инфраструктуры.
Почему это важно для пользователей
Пользователи получают четкую дорожную карту выбора моделей в зависимости от имеющейся видеокарты — от компактных решений для ноутбуков до гигантских систем для исследовательских задач, что позволяет точнее планировать бюджеты на GPU.
Что пока неизвестно / ограничения
Акценты в использовании моделей смещаются от чисто научной новизны к практической применимости для бизнеса и снижению барьера входа для разработчиков.
Источники
Автор
Look at AI, редакция