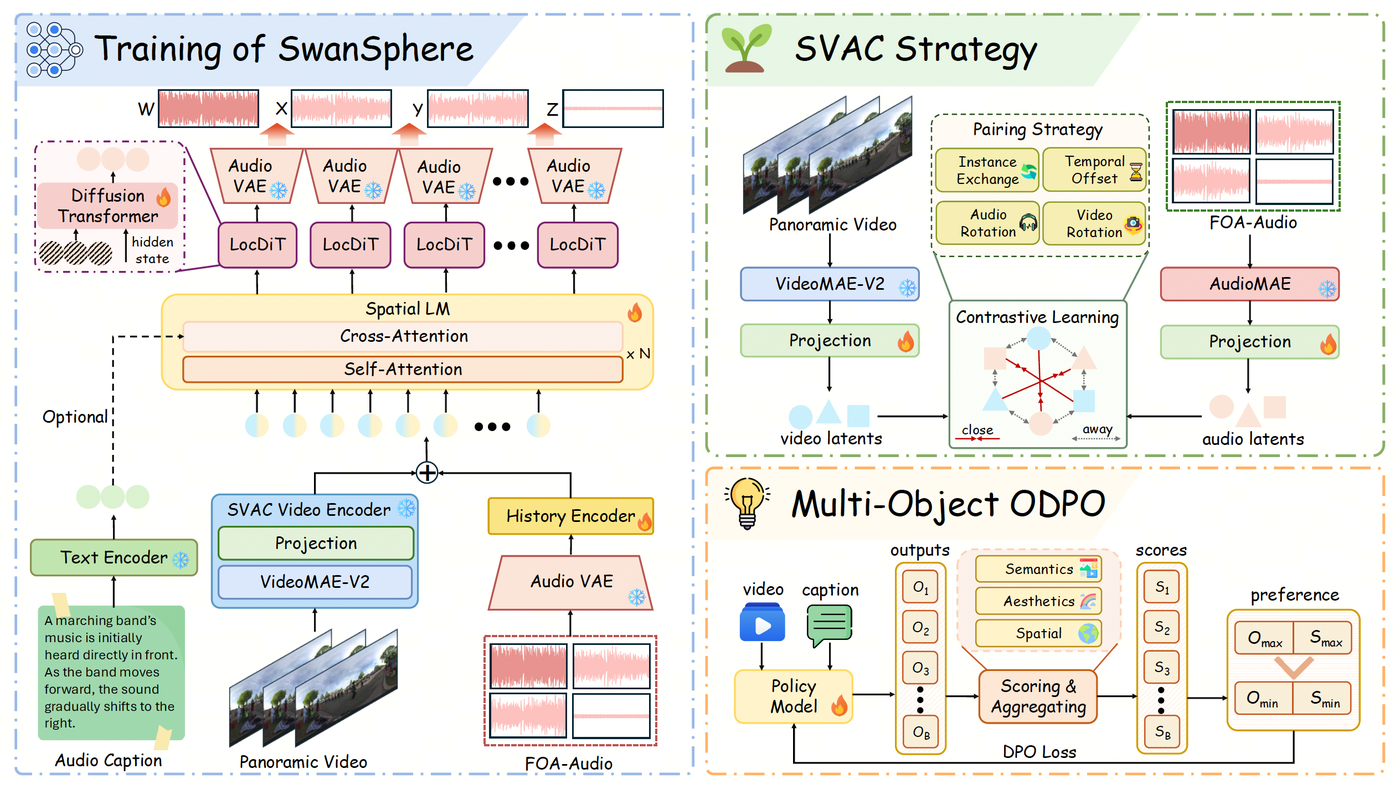
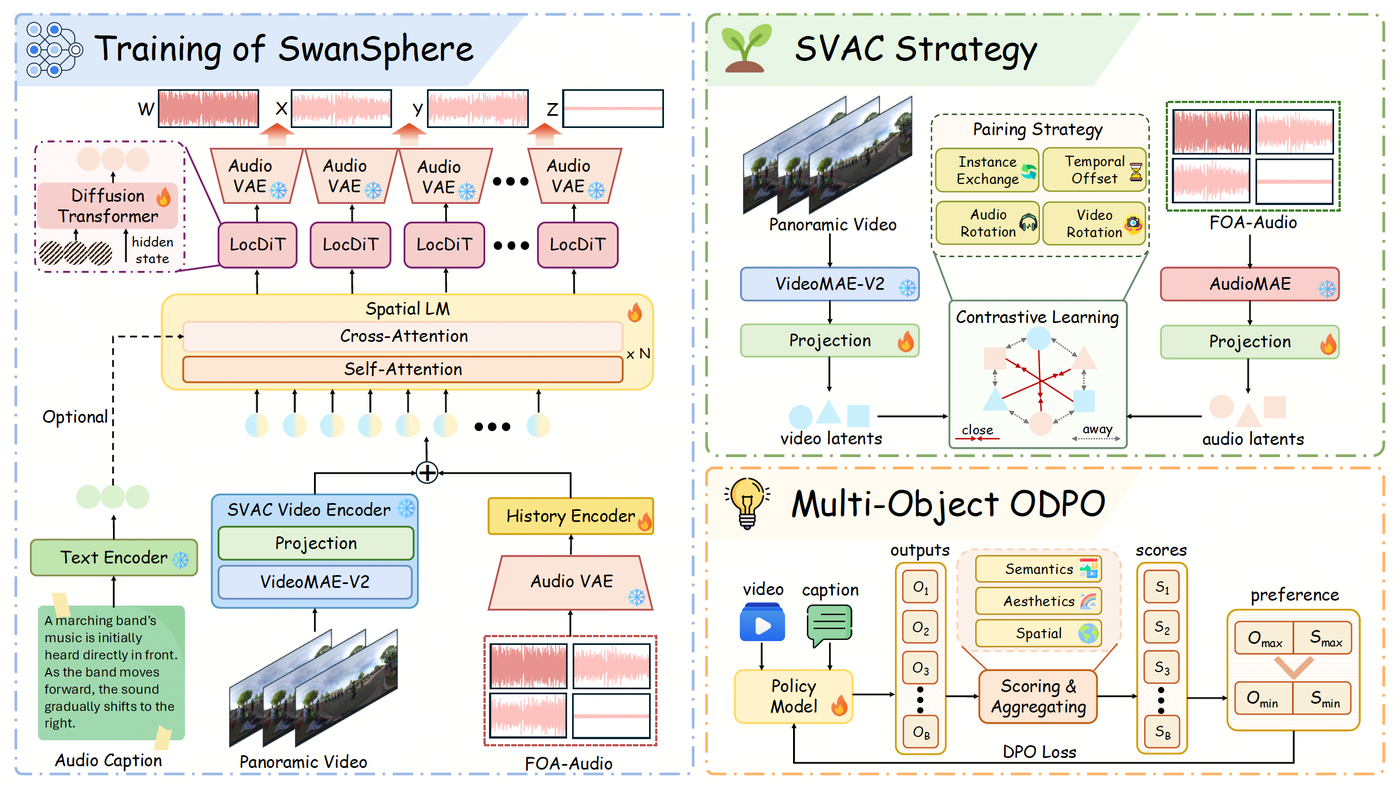
Исследовательская группа SwanAIGC, объединяющая специалистов ByteDance и Университета Чжэцзян, представила SwanSphere — инновационную систему для потоковой генерации пространственного аудио. Проект, принятый на конференцию ICML 2026, использует архитектуру причинного авторегрессионного диффузионного трансформера для создания высококачественного объемного звука в реальном времени на основе текстовых запросов или панорамного видеоряда.
Что произошло
Разработчики представили SwanSphere, которая решает задачу синхронной генерации звука и видео. Система опирается на архитектуру Causal Autoregressive Diffusion Transformer и использует стратегию обучения SVAC (Spatial Video-Audio Contrastive) для точной синхронизации аудио и видео. Кроме того, для повышения качества восприятия пространственности звука применяется метод многоцелевой онлайн-оптимизации прямых предпочтений (ODPO).
Контекст
Традиционно при генерации объемного звука разработчики сталкиваются с жестким компромиссом между высоким качеством аудио и задержкой (latency) при инференсе. SwanSphere предлагает новый архитектурный подход, превращая сложную генерацию пространственного звука в эффективную потоковую задачу, что является важным шагом для мультимодального генеративного ИИ.
Почему это важно для индустрии
Для индустрии это означает преодоление фундаментального барьера задержки, что открывает возможности для создания по-настоящему иммерсивного VR/AR контента с генеративным звуком, работающим в реальном времени. Технология закладывает новую архитектурную базу для мультимодальных исследований и может стать стандартом для генерации foley-звуков в пайплайнах создания видеоконтента.
Почему это важно для пользователей
Для конечных пользователей это означает качественный скачок в потреблении цифрового контента: видео и виртуальные миры смогут звучать объемно и синхронно с картинкой, даже если звук создается нейросетью «на лету» по текстовому описанию или на основе движущегося видеоряда.
Что пока неизвестно / ограничения
На текущий момент эксперты выражают скепсис относительно практической готовности технологии к продакшн-деплою из-за отсутствия открытого исходного кода и детальных технических метрик инференса, таких как конкретные показатели задержки (latency) и пропускной способности (throughput).
Источники
- SwanSphere: Towards Streaming Synchronized Spatial Audio Generation via Autoregressive Diffusion Transformer
- SwanAIGC Official Project Page
Автор
Look at AI, редакция