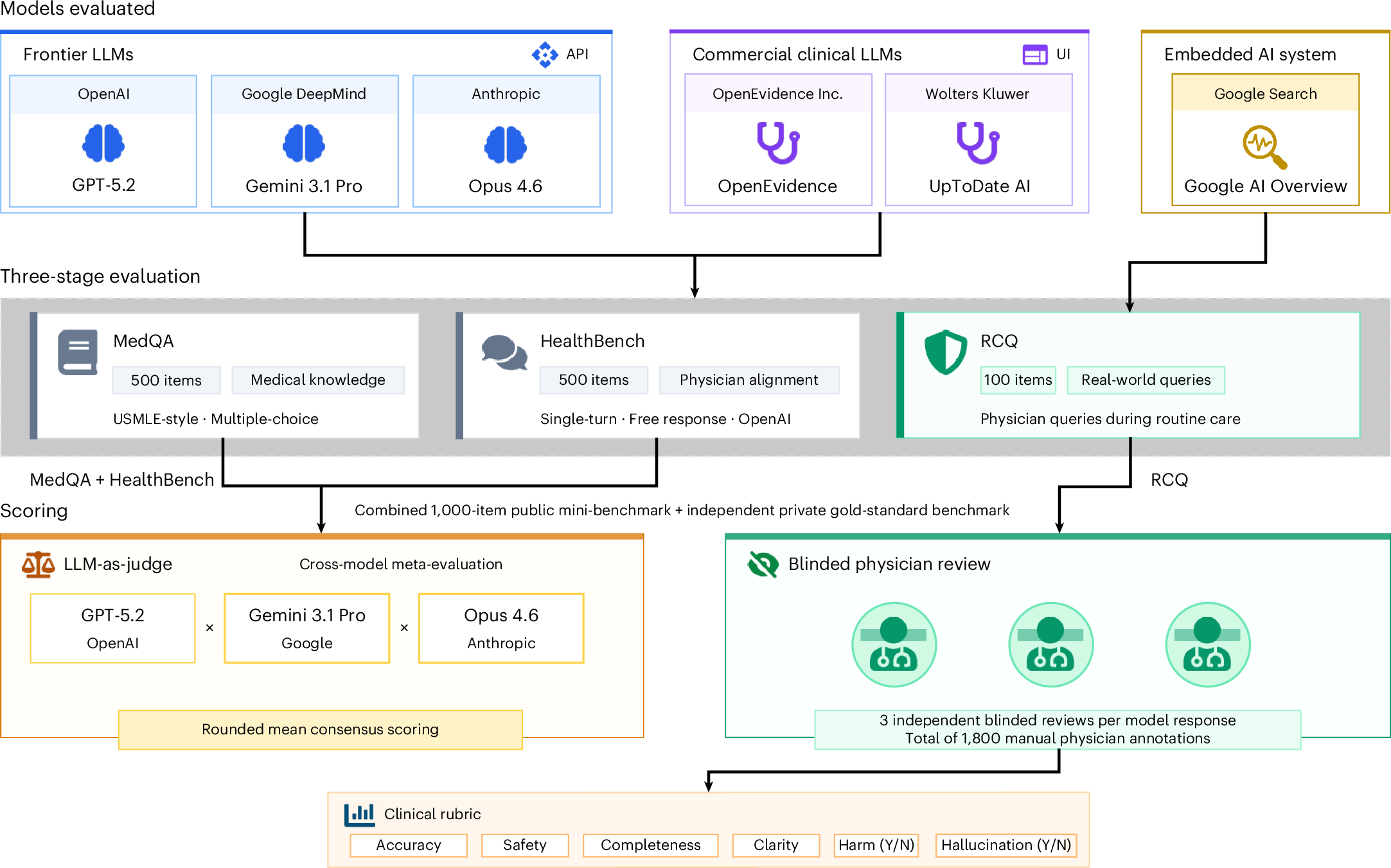
🩺 General-Purpose LLMs Outperform Medical AI
A study in Nature Medicine has shown that general-purpose models (Gemini 3.1 Pro, Claude Opus 4.6) outperform specialized tools (OpenEvidence, UpToDate Expert AI) in medical knowledge tests. In the MedQA test, Gemini 3.1 Pro scored 97.4%, compared to 89.6% for OpenEvidence.
🌍 This calls into question the effectiveness of current specialized RAG systems and could change strategies for medical software development and AI solution procurement.
👤 One should not blindly trust applications labeled as "medical AI" — a top-tier chatbot might prove to be a more accurate assistant.
Source 1: https://www.nature.com/articles/s41591-026-04431-5