The large language model market is actively segmenting based on available video memory (VRAM), offering solutions ranging from compact models for edge devices to giant systems for research clusters.


What Happened
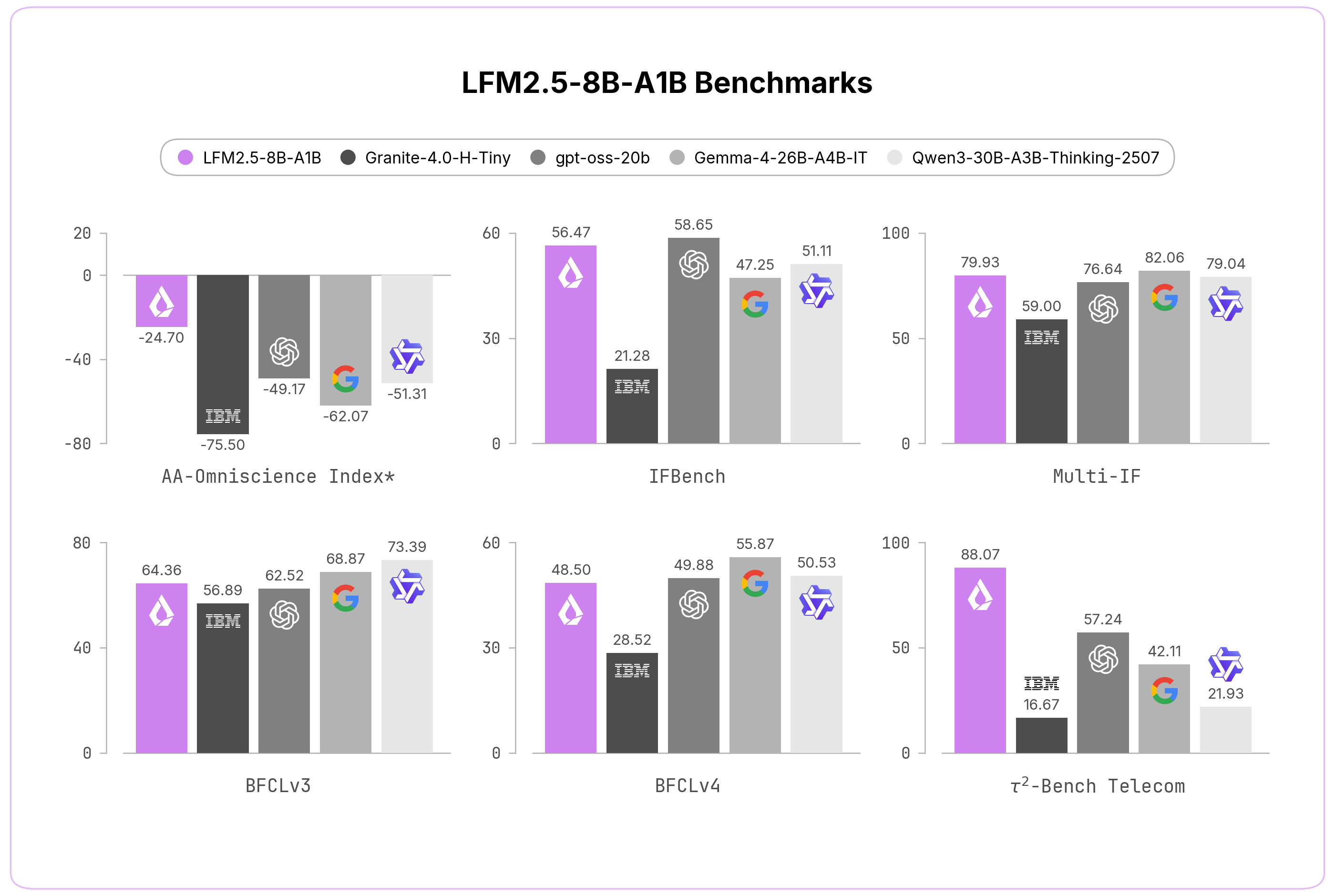
A review of current LLMs optimized for specific VRAM capacities has been presented. In the 8–12 GB segment, LiquidAI LFM2.5-8B-A1B (MoE with 1.5B active parameters) is highlighted. For 16–32 GB, the multimodal Gemma 4 12B from Google is recommended. In the 32–96 GB range, agentic models Nex-N2-Mini and Qwopus 3.6-27B are presented. For systems with 384–768 GB, Nex-N2-Pro and Macaron V1 Preview-749B (based on GLM-5.1) are offered.
Context
The diversity of architectures, such as Mixture of Experts (MoE) and Mixture of Layers (MoL), allows for efficient distribution of computational tasks. This creates the possibility of creating specialized edge agents and cascaded inference systems, where model complexity scales dynamically according to available hardware.
Why It Matters for the Industry
Expanding the accessibility of high-performance models through optimized architectures allows powerful AI agents to run on consumer and semi-professional hardware, reducing dependence on cloud infrastructure.
Why It Matters for Users
Users receive a clear roadmap for choosing models depending on their available graphics card—from compact solutions for laptops to giant systems for research tasks, allowing for more accurate GPU budget planning.
What Is Not Yet Known / Limitations
The focus of model usage is shifting from pure scientific novelty toward practical applicability for business and lowering the barrier to entry for developers.
Sources
Author
Look at AI, Editorial Team