
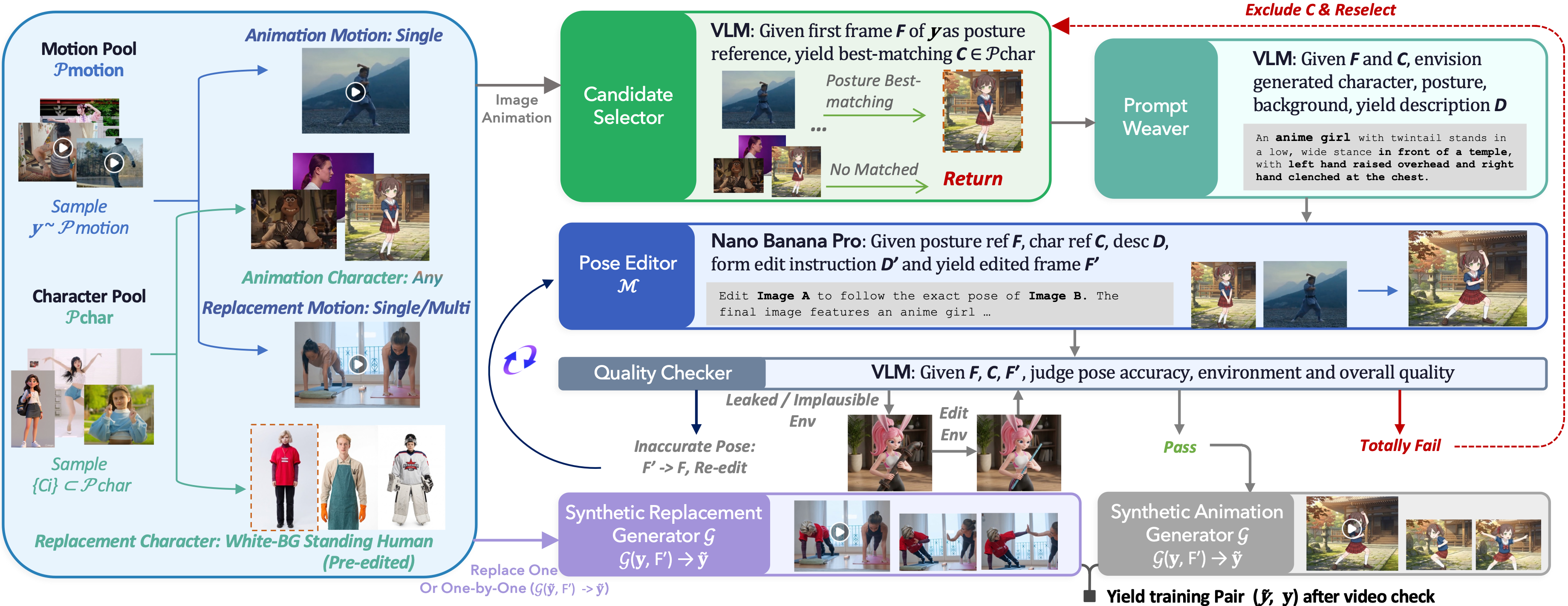
SCAIL-2 has been introduced—an innovative architecture for end-to-end character animation that rejects intermediate skeletal maps or masks in favor of direct visual control. Trained on the synthetic MotionPair-60K dataset, the model enables not only video-based animation but also character replacement and multi-character animation with high motion accuracy.

What Happened
Developers have presented SCAIL-2, which utilizes a latent diffusion model with In-Context Mask Conditioning and Mode-Specific RoPE mechanisms. The architecture allows for character animation using video references directly, ensuring accuracy even in complex hand and finger movements thanks to the Bias-Aware DPO method.
Context
Traditional character animation methods typically rely on multi-stage pipelines involving pose estimation and the creation of intermediate skeletal models or masks. Such approaches often suffer from error accumulation and ambiguity when objects overlap in the frame.
Why It Matters for the Industry
SCAIL-2 eliminates the limitations of intermediate representations, simplifying video generation pipelines and paving the way for more natural animation in complex scenes with multiple characters. This could lead to an industry shift from rigid skeletal systems to flexible diffusion models with direct visual feature control.
Why It Matters for Users
Users gain the ability to perform zero-shot animation using not only humans but also animals or first-person videos as references. Additionally, the technology allows for easy character replacement in existing videos without loss of quality or the appearance of artifacts at the seams.
What Is Not Yet Known / Limitations
At its current stage, the technology is presented primarily as research code and requires significant computational resources for inference due to the use of latent diffusion. Further evaluation of its readiness for industrial production (production-ready) is required.
Sources
Author
Look at AI, Editorial Team