
A new study on the efficiency of small language models (less than 1B parameters) on the NVIDIA Jetson Orin Nano Super 8GB platform has shown that proper power mode configuration and the selection of a specialized backend can significantly increase edge computing performance.

What Happened
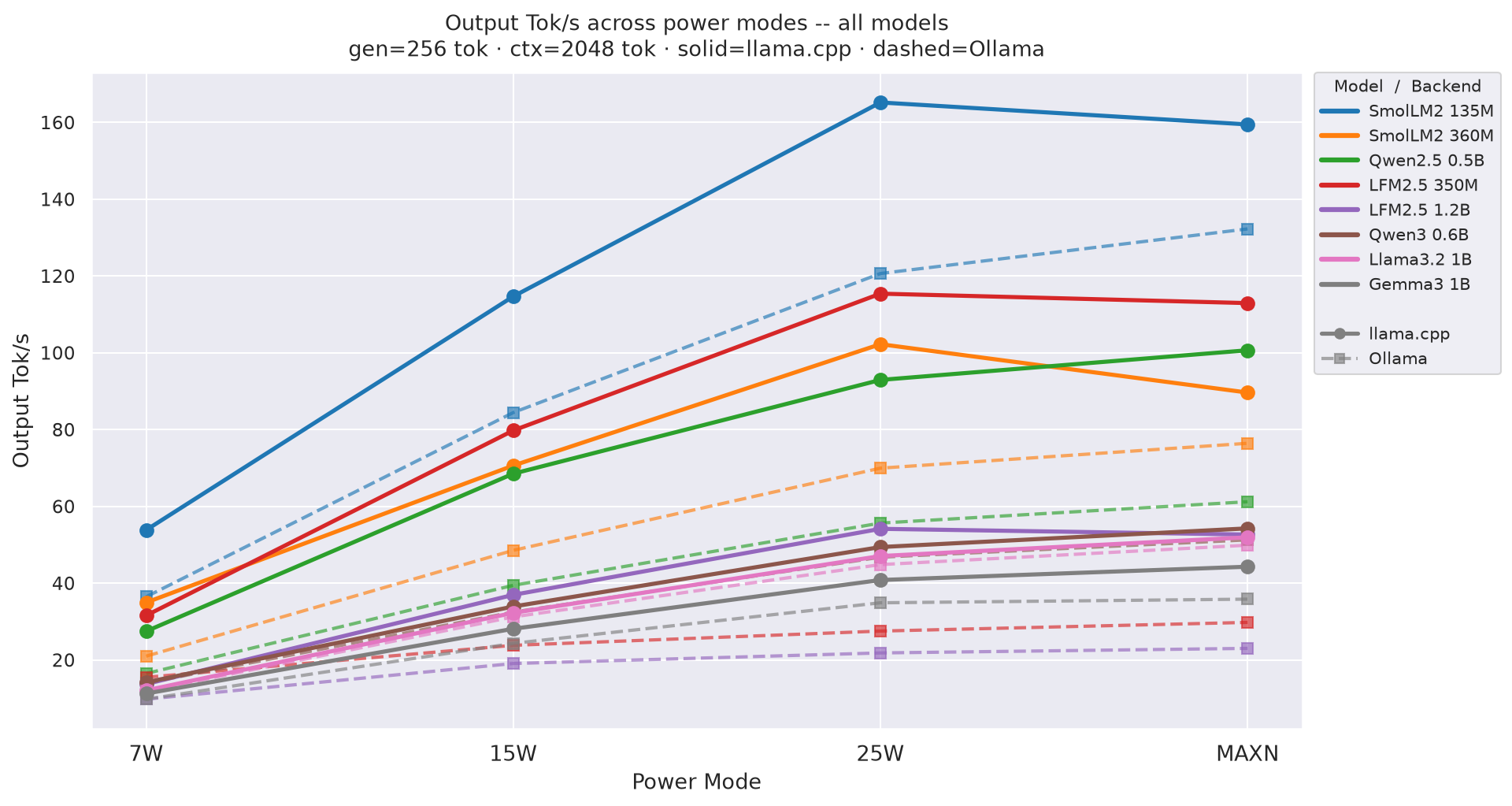
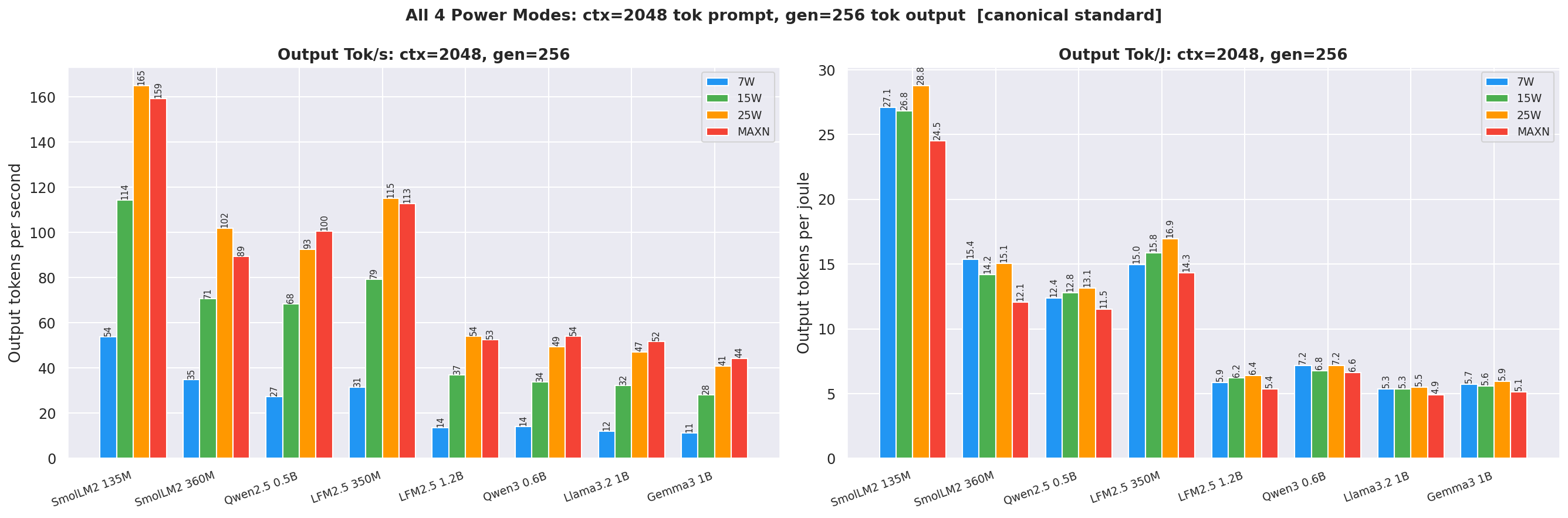
During the benchmark, it was established that using the 25W power mode for the llama.cpp backend provides 35–47% higher throughput than using the 15W mode. Among the tested models, SmolLM2-135M demonstrated the best energy efficiency, achieving a result of 29.6 tok/J with a generation speed of 165.2 tok/s.
Context
Low-level optimization is critical for the effective deployment of AI on compact devices. There is a noticeable performance gap between specialized tools like llama.cpp and more universal solutions like Ollama, which can run up to 4 times slower on specific models.
Why It Matters for the Industry
The results highlight the need for deep CUDA kernel optimization for new architectures, such as SSM in LFM2.5. For the edge-AI industry, this means a transition from simply running models to standardizing optimized runtime environments, where backend efficiency becomes a determining factor in device cost and capability.
Why It Matters for Users
Developers of local AI solutions based on NVIDIA hardware are recommended to use the 25W power mode and the llama.cpp backend to achieve the best balance between speed and power consumption on Jetson Orin Nano Super devices.
Sources
Author
Look at AI, Editorial Team