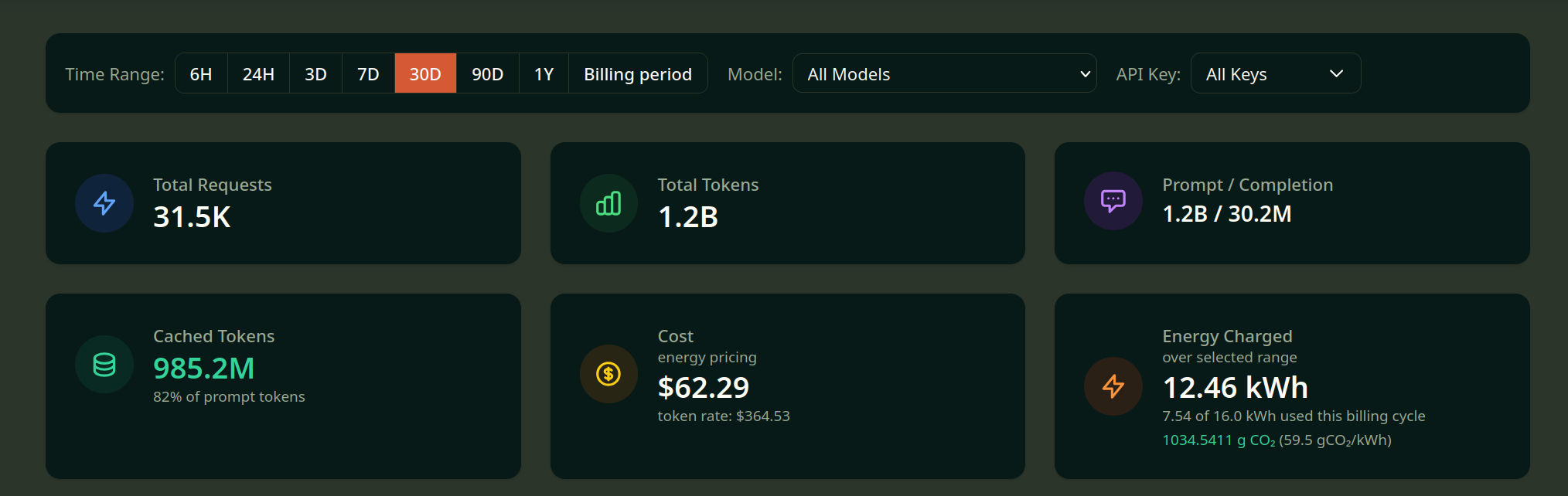
Startup NeuralWatt is introducing a revolutionary pricing model for Large Language Model (LLM) inference based on actual electricity consumption (kWh) rather than the number of generated tokens. This approach allows for a radical reduction in operational costs, especially when using efficient open-weights models.

What Happened
NeuralWatt has proposed a shift from traditional pay-per-token models to one tied to energy consumption. According to user data, using this model for the Qwen and Kimi model families allowed for an average cost reduction of 82.9%. In specific cases, such as for the qwen3.6-35b-fast model, savings reached as high as 95.2%.
Context
The traditional pay-per-token model does not always account for the actual computational load and the efficiency of the provider's infrastructure. Moving to energy-based pricing makes the cost directly dependent on caching efficiency and GPU/NPU utilization optimization, creating incentives to develop more advanced hosting methods.
Why It Matters for the Industry
For the industry, this means a potential shift in the economics of cloud inference. The emergence of an energy-based pricing model encourages providers to invest in energy efficiency and "green" AI hosting. This could lead to increased competition and the destabilization of standard token prices as new players emerge, focused on minimizing kWh per request.
Why It Matters for Users
Developers and companies with high LLM workloads can significantly reduce their OPEX, especially when working with open-weights models. Transitioning to an energy-based model provides more predictable costs for intensive and repetitive requests, where caching efficiency plays a decisive role.
What Is Not Yet Known / Limitations
Technical specialists and architects express moderate skepticism, pointing to the need for verification of the accuracy of energy consumption measurements and potential complexities when integrating such a model into existing workflows.
Sources
Author
Look at AI, Editorial Team