
MetalBear developers have introduced a new method for verifying solutions proposed by the HolmesGPT AI-SRE agent using the capabilities of the mirrord tool. This approach allows for testing code changes directly within the context of a real Kubernetes cluster, ensuring high verification accuracy without the need for a full infrastructure deployment.

What Happened
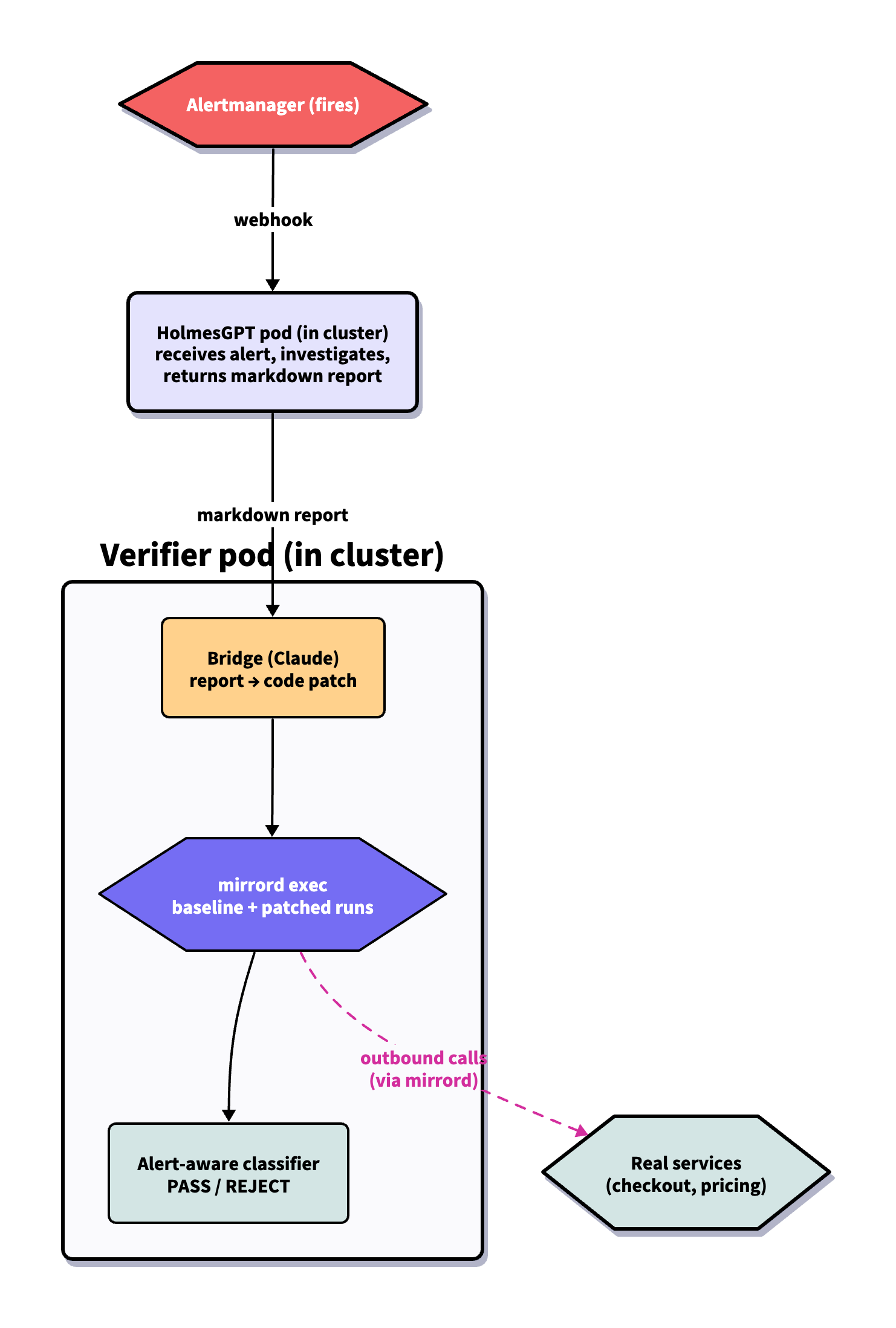
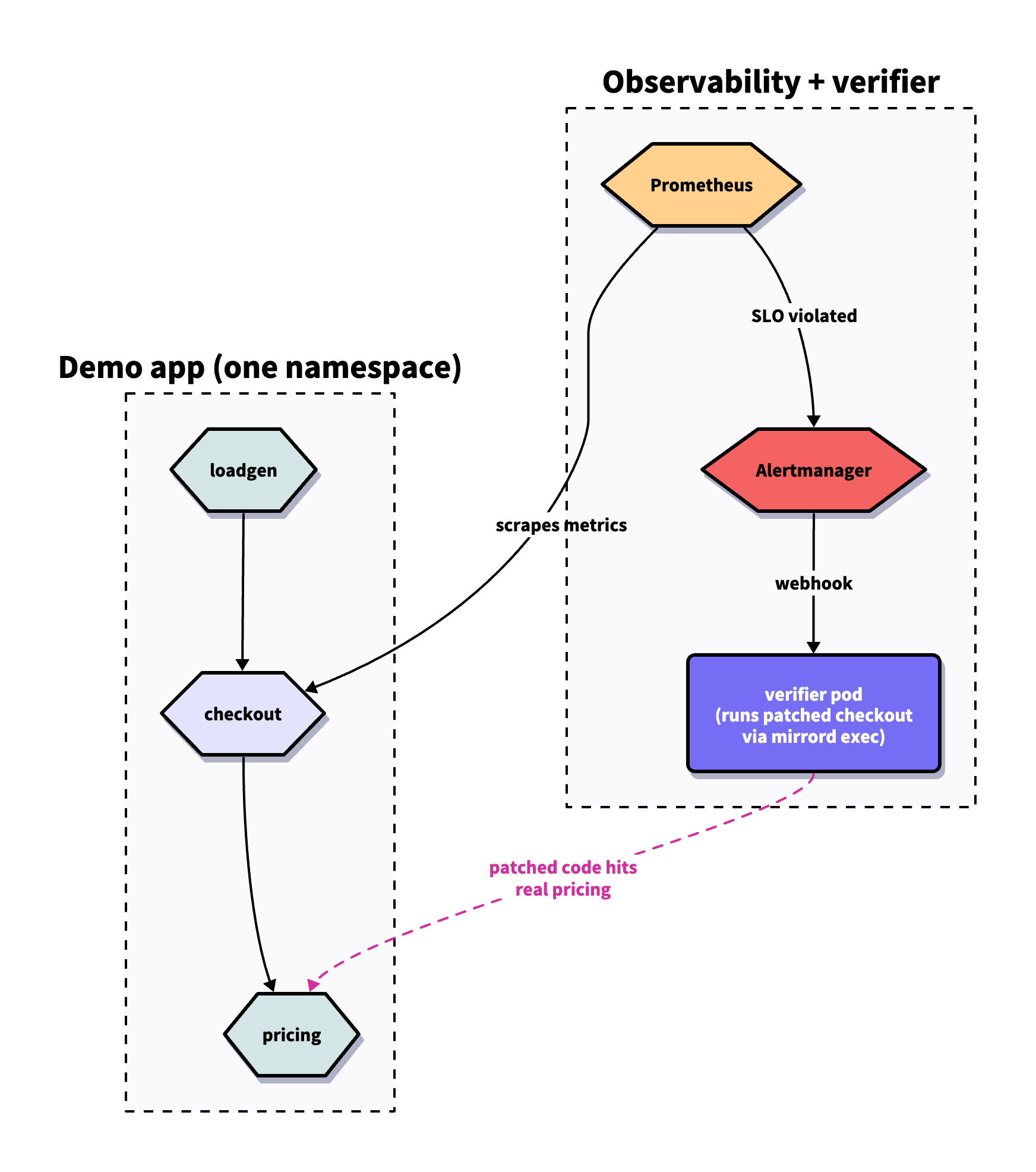
MetalBear demonstrated the integration of the HolmesGPT agent with the mirrord tool to automate patch verification. Using the mirrord exec command, fixes are run inside an existing Kubernetes cluster, allowing them to inherit network identity, environment variables, and mounts. This makes it possible to distinguish truly effective fixes (e.g., those eliminating 500 errors) from ineffective ones that might improve average metrics (p50) but fail to resolve latency issues (p99 latency).
Context
Traditional LLM agents often act merely as "advice" or code generators, lacking the ability to verify their suggestions in a real operational environment. There is a critical problem with "one-off" agents that may propose incorrect solutions without understanding the infrastructure context. Integrating AI with deep testing and network simulation tools allows for a transition from theoretical code writing to a full "proposal — verification — application" cycle.
Why It Matters for the Industry
For the industry, this signifies the transition of AI agents from the category of auxiliary tools to full participants in Operations and CI/CD processes. The emergence of such methods creates a reliable way to bring AI-SRE tools to market, reducing risks associated with model "hallucinations" in production environments, and laying the foundation for standards in autonomous self-healing infrastructure management.
Why It Matters for Users
For engineers and users, this is a significant step toward autonomous infrastructure management. Instead of blindly trusting an AI agent, an automatic verification cycle can be implemented, where every patch is checked for compliance with Service Level Objectives (SLO) in a staging environment that closely mimics reality before it reaches a human for review.
Sources
Author
Look at AI, Editorial Team