Liquid AI has introduced new multilingual retrieval models, LFM2.5-Embedding-350M and LFM2.5-ColBERT-350M, which demonstrate exceptional speed and efficiency in retrieval tasks.
What Happened
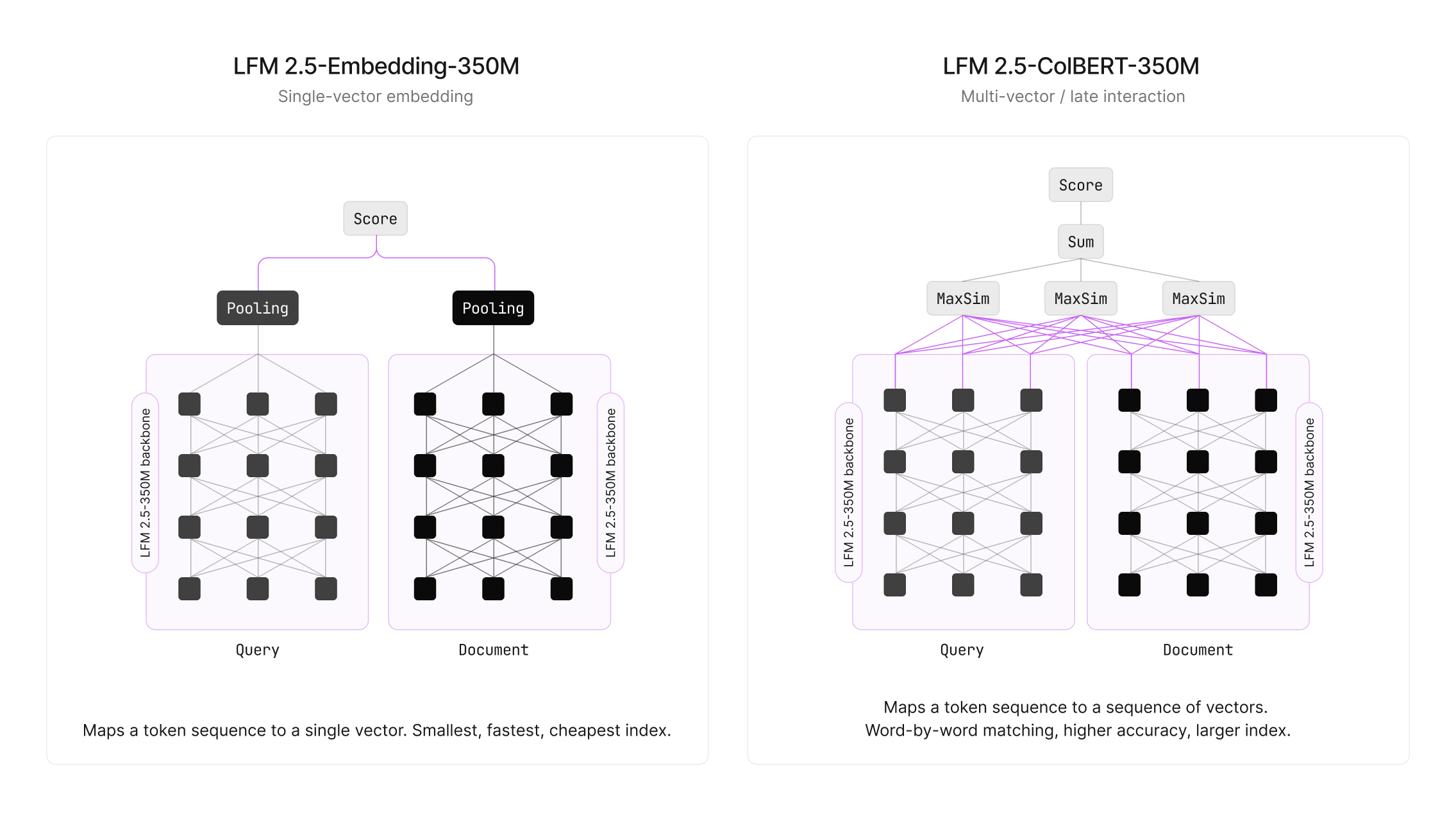
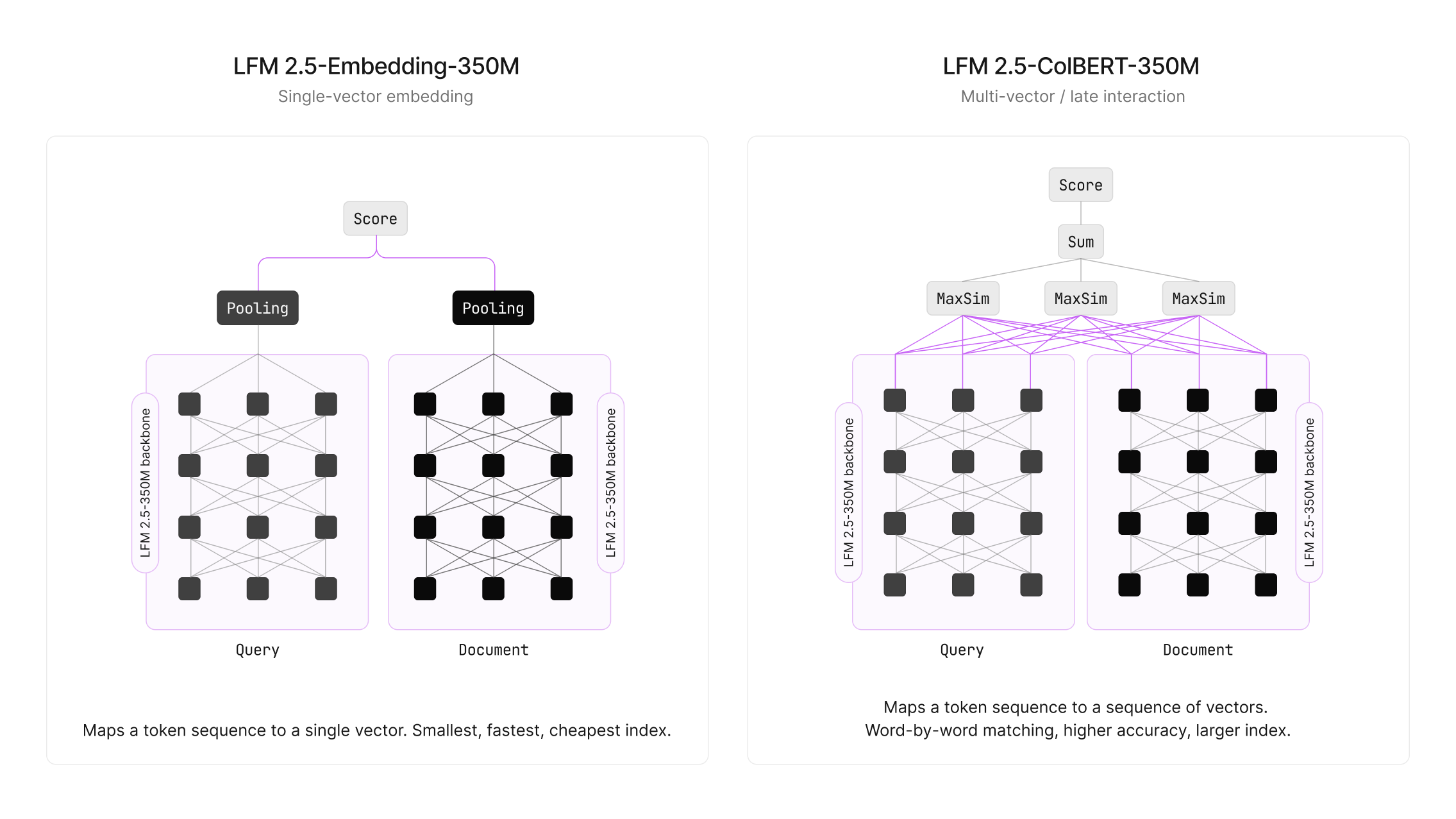
Liquid AI released two compact 350M parameter models: LFM2.5-Embedding-350M and LFM2.5-ColBERT-350M. These are the first bidirectional models in the LFM family, created by modifying the LFM2.5-350M-Base architecture (removing the causal mask and transitioning to symmetric convolutions). The models support 11 languages. On H100 hardware, ColBERT latency is approximately 2.5 ms (p50), and on a MacBook M4 Max, it is approximately 7-8 ms (p50).
Context
The architectural shift involves moving from a causal decoder to a bidirectional encoder. Using symmetric convolutions instead of a causal mask allows the models to utilize context in both directions, which is critical for embedding quality. Notably, the ColBERT model (0.605 NDCG@10 on NanoBEIR) outperforms existing solutions such as Qwen3-Embedding-0.6B (0.556) and gte-multilingual-base (0.528), despite having fewer parameters.
Why It Matters for the Industry
The emergence of efficient and compact bidirectional encoders allows for significantly reducing the cost and latency of deploying RAG (Retrieval-Augmented Generation) systems and search engines. This paves the way for high-performance edge solutions and reduces dependency on heavy cloud APIs and massive models in multilingual environments.
Why It Matters for Users
Users gain the ability to run high-quality search and FAQ systems locally on powerful laptops or inexpensive hardware with very high response speeds, while ensuring a high level of data privacy.
Sources
Author
Look at AI, Editorial Team